图像美学评价的相关论文
Theme-Aware:
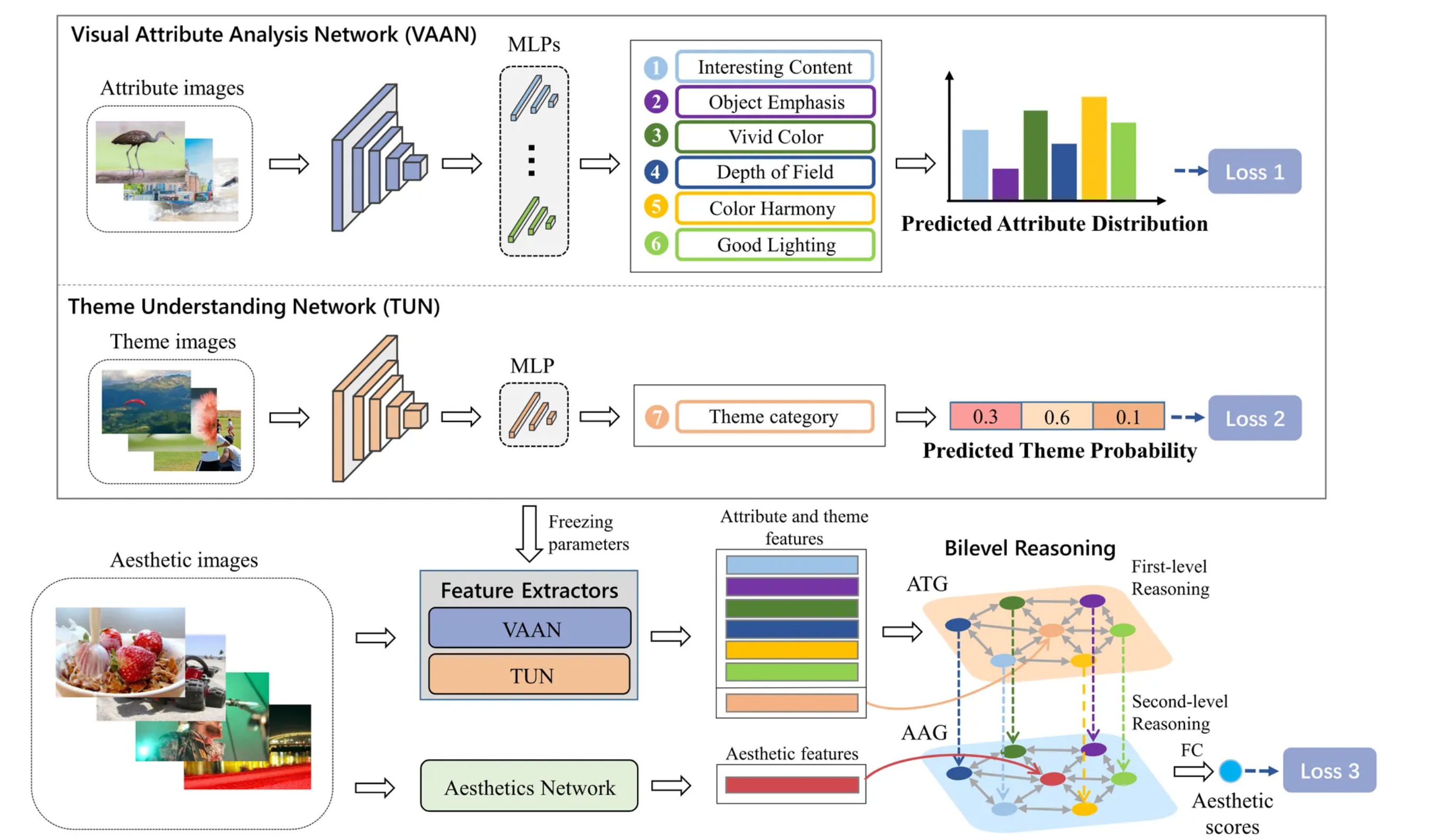
总体结构。1 )预训练视觉属性分析网络( VAAN )提取视觉属性特征。2 )对主题理解网络( TUN )进行预训练,提取图像主题特征。3 )利用美学网络提取通用的美学特征。4 )利用属性-主题图( ATG )挖掘图像主题与视觉属性之间的关系。5 )利用属性美学图( AAG )进一步挖掘主题感知视觉属性与通用美学特征之间的关系。
可解释性:
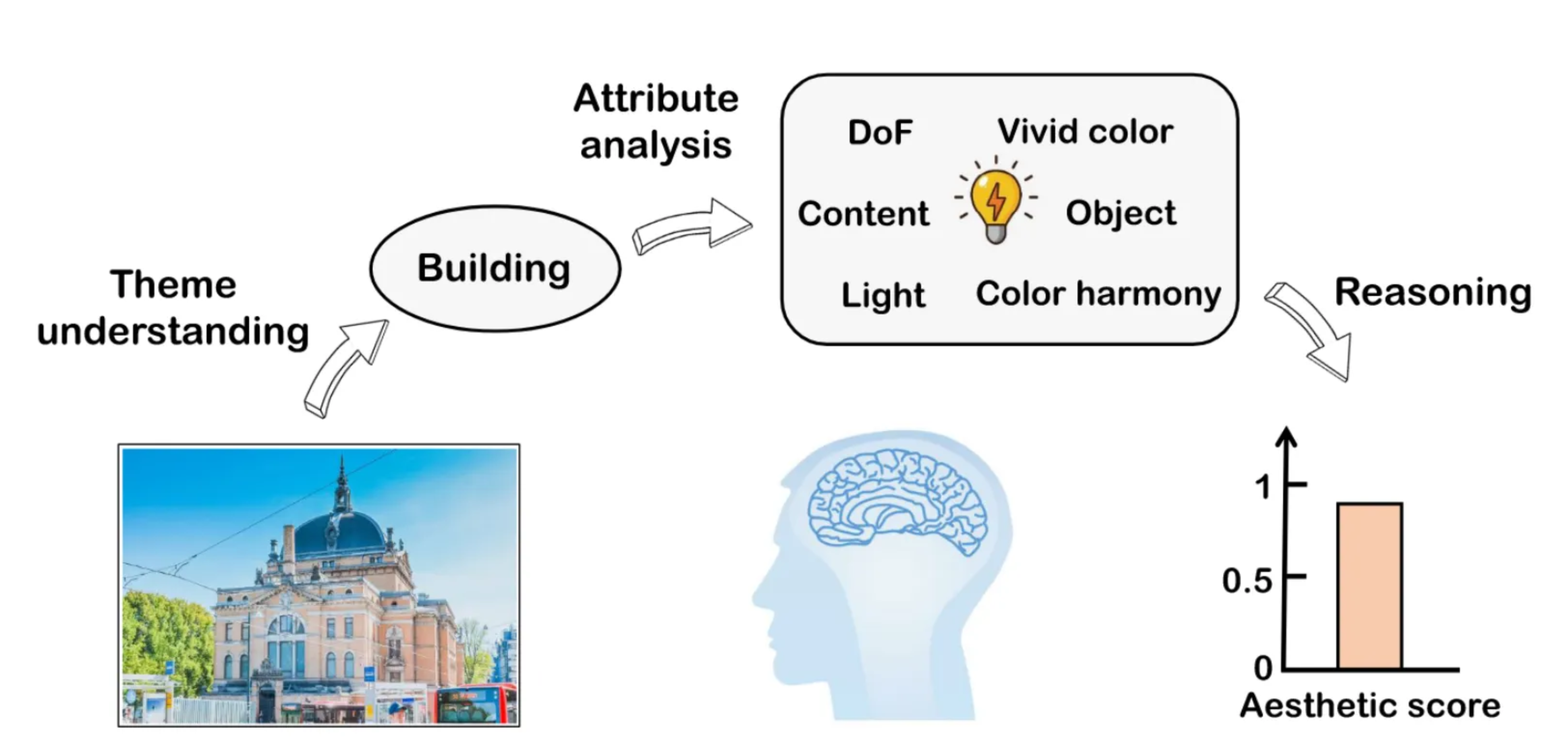
Ic:有趣的内容;Oe:对象强调;Vc:鲜艳的颜色;Dof:景深;Ch:色彩和谐;G1:良好的照明;Gt:事实真相;pre:预测。
explainable可解释:
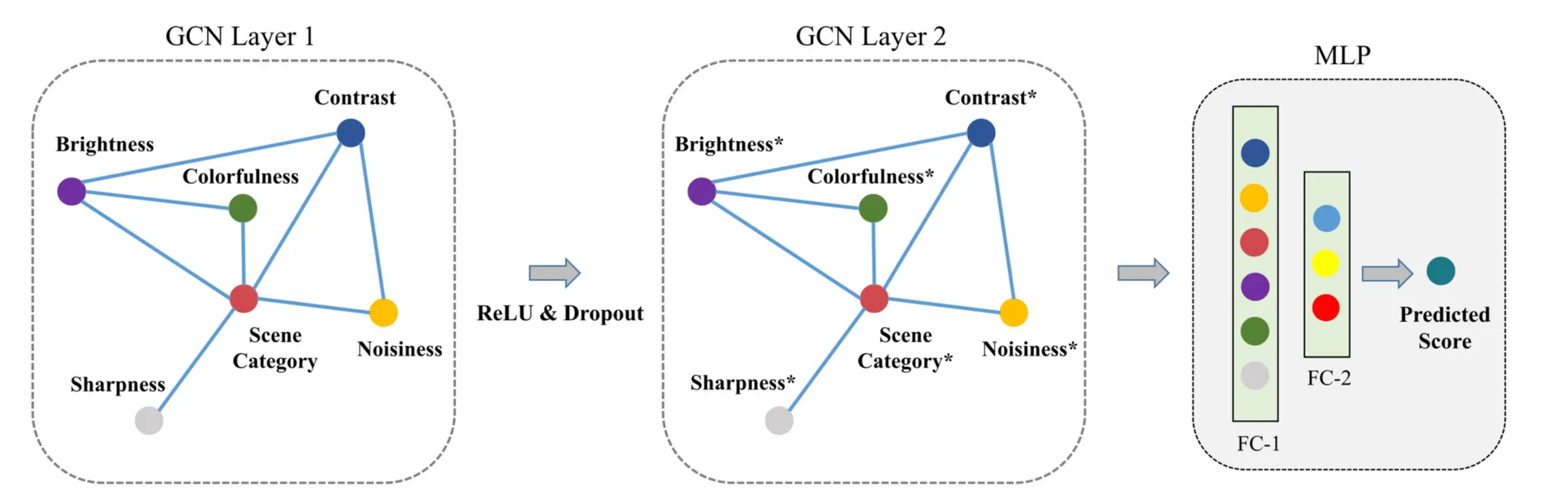
图神经网络(GCN)建模语义属性与场景类别的关系,以提高模型的解释性和泛化能力。
可解释指的是为什么分数比较高,相当于把分数解析为多个属性,分数解耦?
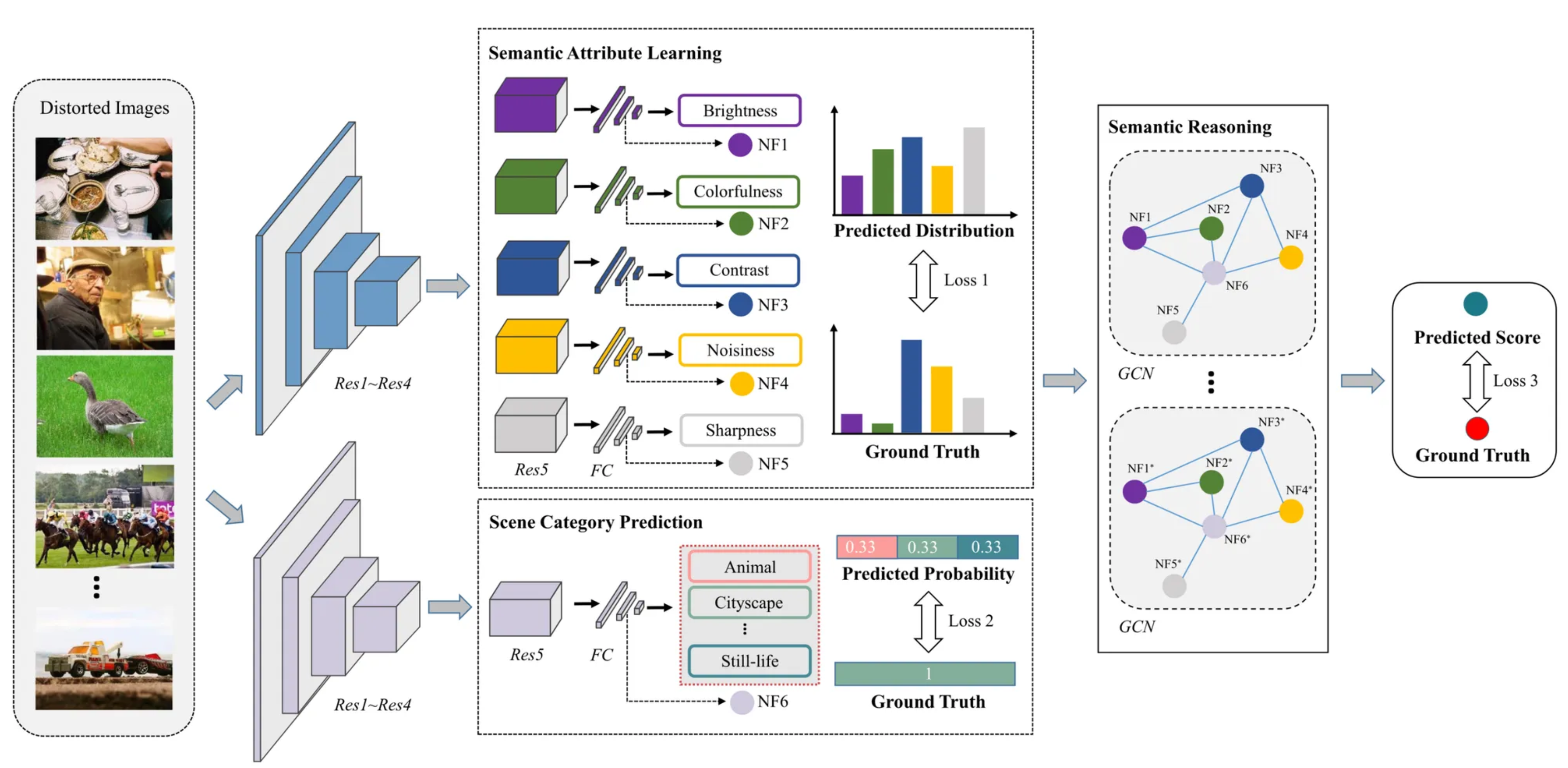
总体框架:
- 语义属性学习模块:利用多分支卷积网络预测五种语义属性(亮度、色彩、对比度、噪声、锐度)。
- 场景类别预测模块:通过ResNet-50预测图像的场景类别。
- 语义推理模块:基于GCN,挖掘语义属性与场景类别之间的内在关系,生成最终的图像质量分数。
2.2 模块细节
语义属性学习
- 通过ResNet-50提取图像特征并利用多分支网络分别预测五种语义属性。
- 损失函数:采用L1损失优化参数,保证预测语义属性与真实值的接近性。
场景类别预测
- 使用ResNet-50提取特征,并通过全连接层预测场景类别概率。
- 损失函数:采用L1损失优化预测类别与真实类别的差异。
语义推理
- 使用GCN建模语义属性与场景类别的关系,设计自定义的邻接矩阵表示节点间的关系。
- 最终通过多层感知机(MLP)生成质量分数。
可解释性:
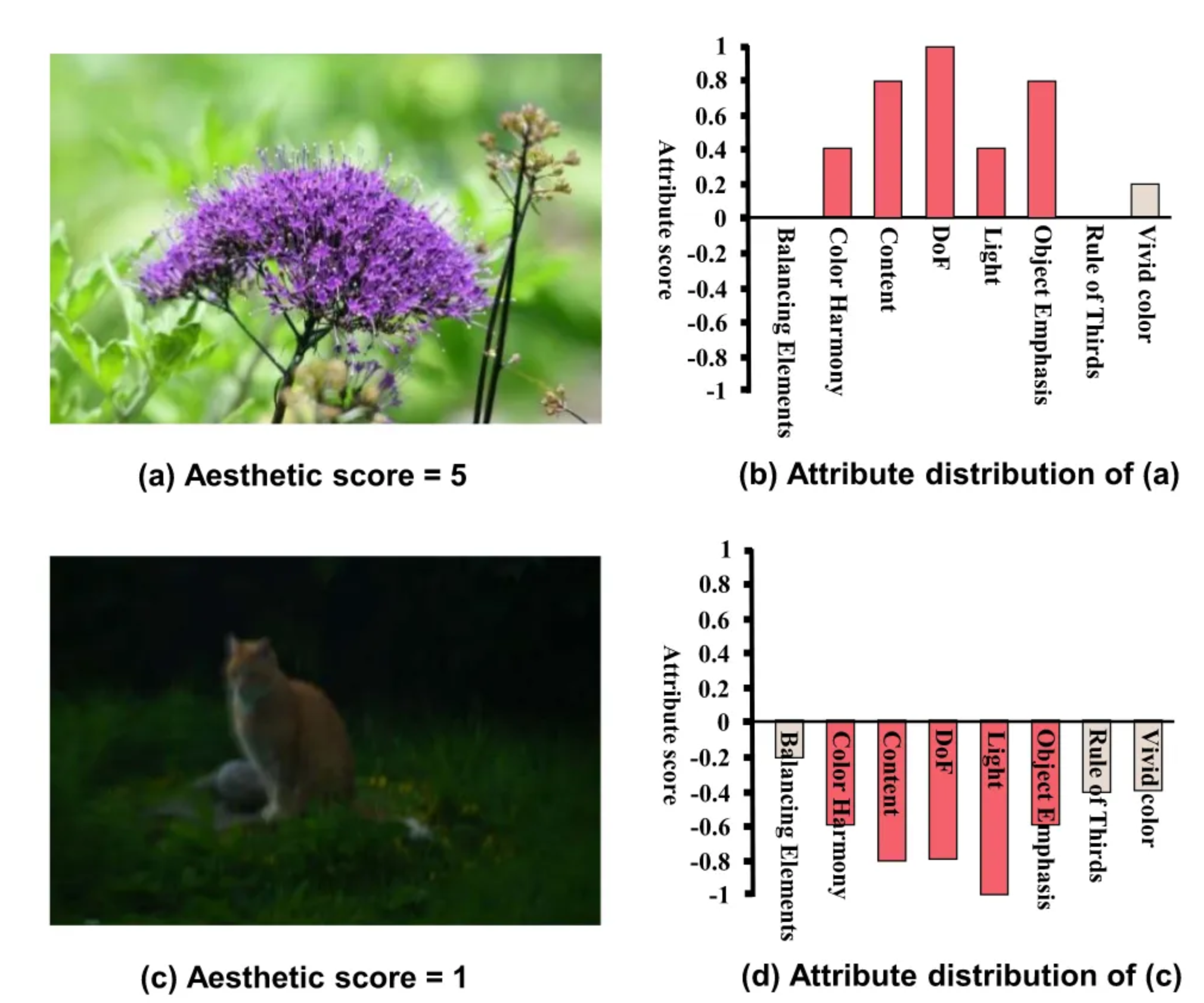
可视化生成的激活图表明,SARQUE能有效捕捉影响图像质量的区域,且其预测的语义属性与人类感知一致。
生成分数分布,不是分数回归,可以看到不同子动作对分数分布的影响。

Coarse
关键创新
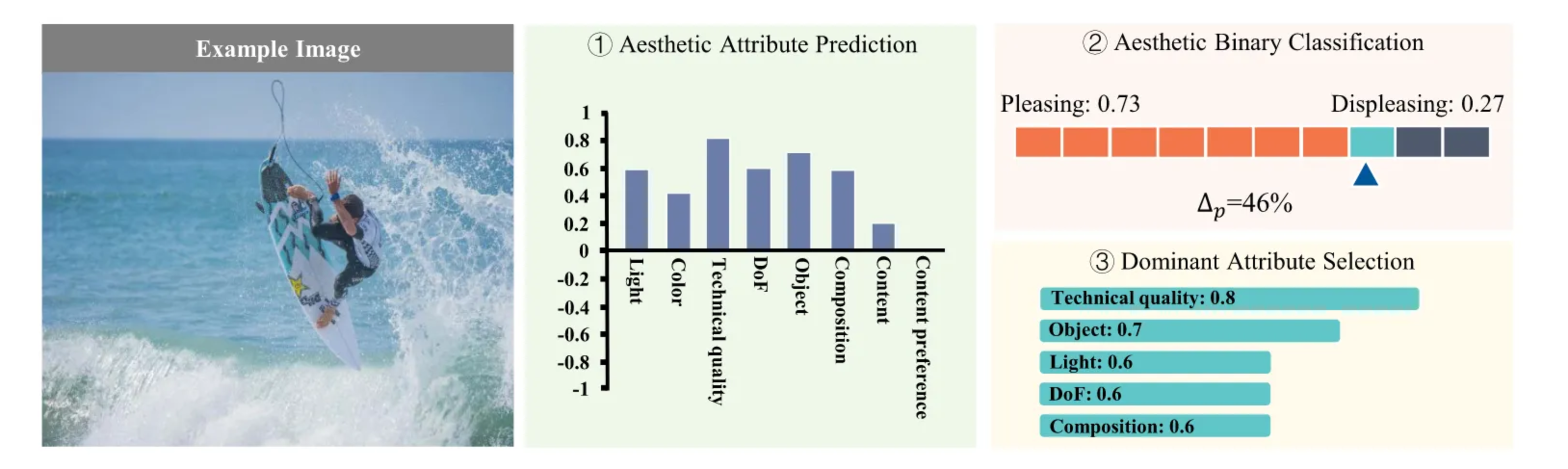
- 粗到精的美学评估:首先进行粗粒度的二分类任务,然后进行更复杂的美学分数预测。
- 动态属性选择:根据预测的美学二分类结果动态选择显著影响美学评分的属性。
- 自注意力融合网络:使用自注意力机制探索美学属性与图像特征的交互,以提高最终的美学预测性能。
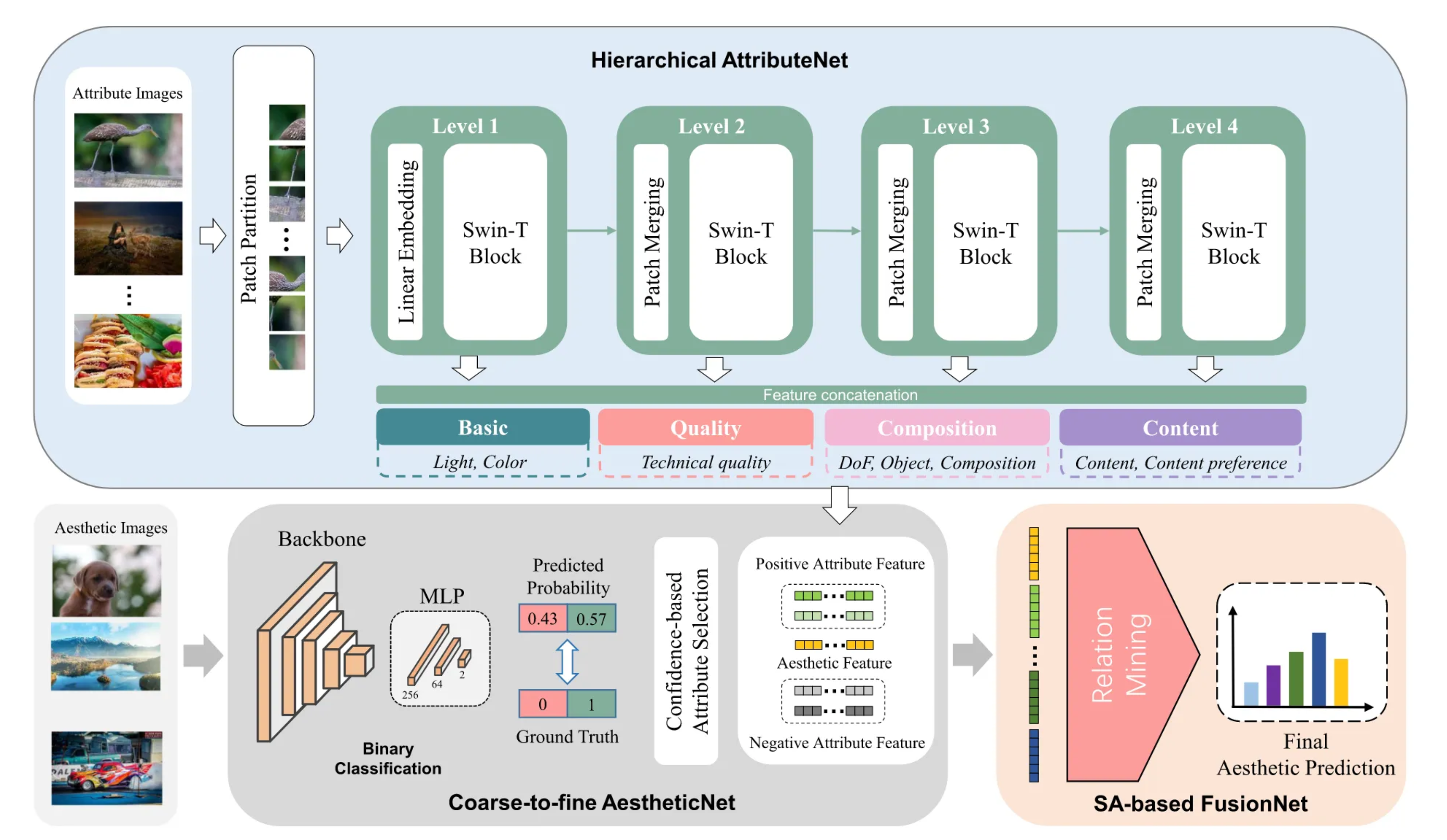
CADAS模型主要由三个部分组成:
- AttributeNet:一个层次化的网络,用于预测图像的候选美学属性。
- AestheticNet:用于进行粗粒度的美学二分类,判断图像是否美观。
- FusionNet:基于自注意力机制,融合从AestheticNet和AttributeNet中提取的特征,以进行精细的美学评分预测。
根据心理学研究,图像的美学属性可以分为低级特征和高级特征。例如,光线和色彩属于低级特征,而构图和内容属于高级特征。AttributeNet通过层次化方式将这些属性分组并进行预测。
可解释性分析
CADAS不仅能够输出最终的美学评分,还能够预测图像中最具影响力的美学属性。通过对比高、美、中、低美学评分的图像,实验展示了CADAS如何通过选择和分析图像的显著美学属性提供直观的解释。
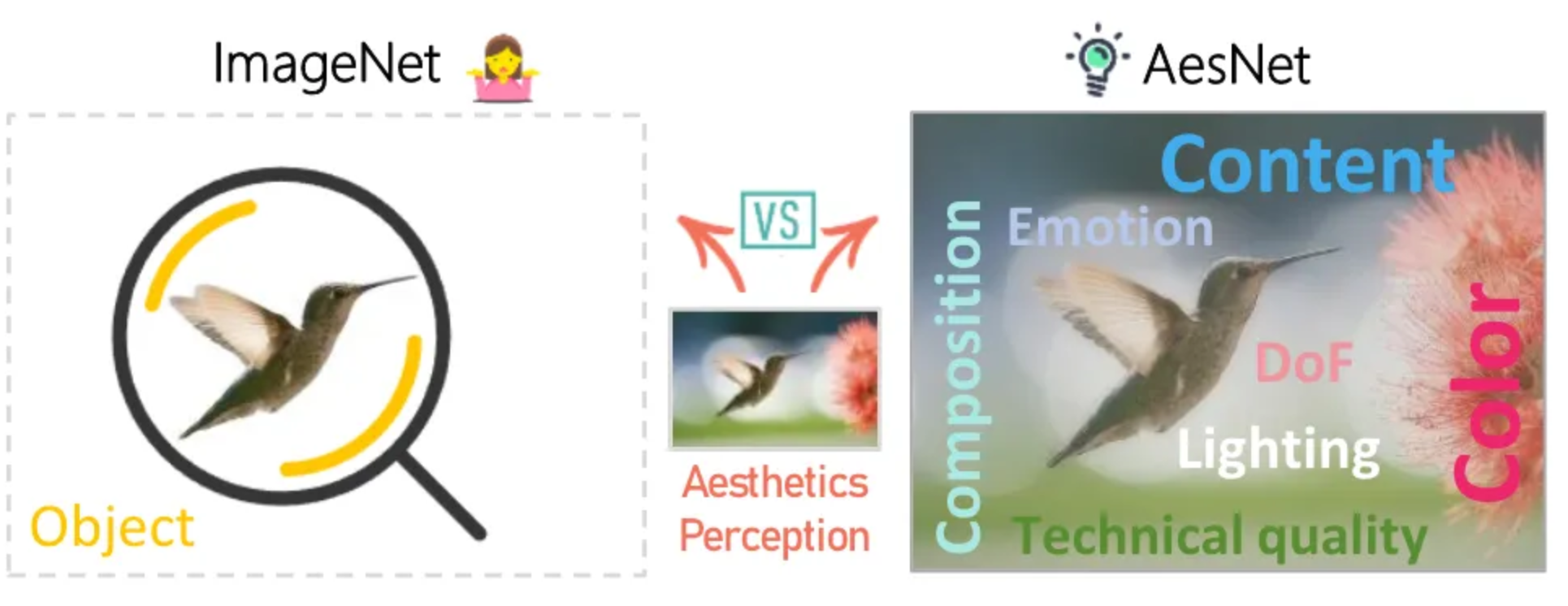
Multi-modality-IAC预处理:
动机:图像分类的预处理模型,主要强调图像的分类特征,而不是美学评价需要的特征属性。
需要解决的问题: 1:属性数据- 数据用多模态大语言模型(MLLM)生成 2:描述数据的特征。-多属性对比学习
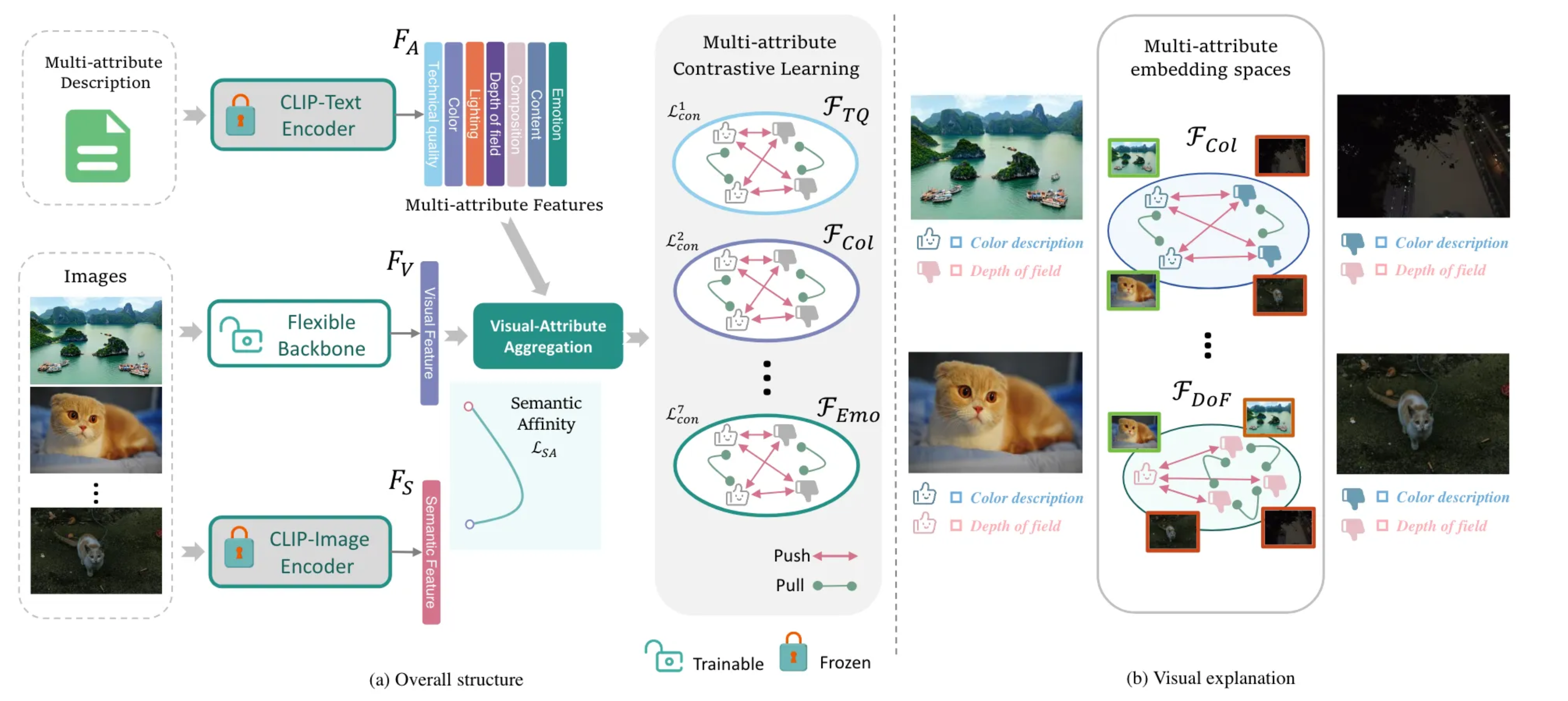
方法:
- AesNet将基于图像的视觉特征与基于文本的属性特征融合,通过映射到不同的嵌入空间中,进行多属性对比学习。这种方法能够有效地区分相似和不相似的样本,从而获得更全面的美学表示。
- 通过引入语义亲和损失,本文解决了从通用视觉领域到美学领域过渡时的分布变化问题,提升了模型的泛化能力。
语义亲和损失: 为了减轻从一般视觉领域到美学领域的分布转移,本文提出了语义亲和损失(Semantic Affinity Loss),通过约束图像的视觉信息与美学语义信息的一致性,帮助模型保留内容信息并增强其泛化能力。
多属性对比学习
- 特征融合:通过视觉-属性聚合模块,将图像的视觉特征与七种美学属性的文本特征进行融合。这些融合特征被映射到七个不同的嵌入空间中,进行多属性对比学习,以学习到更加丰富的美学表示。
- 对比学习损失:通过对比学习方法,模型在不同属性的嵌入空间中优化,拉近相似样本的距离,推远不相似样本的距离,最终提升美学特征的区分能力。 对比学习已经被证明能增强特征表示。
- 语义亲和损失:为了缓解视觉信息和美学信息之间的分布差异,提出语义亲和损失,以确保模型能够保留更多的内容信息,从而增强其在实际美学任务中的泛化能力。
AesExpert多模态美学专家模型
大语言模型构建了一个数据集
8块A100训练。