Else-Net基于骨架的连续动作识别弹性特征选择
评价
尽管作者已经为解决这个任务做出了努力,但他们采用了一种可扩展的架构,这种架构可以在每次出现新的类时为网络添加一个新的可学习模块。虽然这种技术有助于减轻灾难性遗忘,但模型的计算足迹逐渐增长,使得该方法耗费内存且可扩展性差。此外,它们的设置增加了与真实世界场景不同的约束。也就是说,他们在大多数训练实例上预训练网络,并且在增量阶段只保留几个类。他们使用NTU RGB + D 60的前50个类预训练他们的网络,并在10个任务上进行增量训练,每个任务聚焦于一个不同的类。我们认为这样的基准不同于经典的CL基准,因为它是简化的并且远离真实世界的场景。
论文
1. 引言
背景:
现有动作识别方法多为离线学习,需要所有类别数据同时可用。然而,实际应用中,如人机交互和安防监控,模型需处理连续流式的新动作数据,这对模型提出了持续学习的挑战。问题:
持续学习面临 灾难性遗忘 (Catastrophic Forgetting) 问题,新学习的动作会覆盖之前学到的知识。灵感来源:
人类大脑通过在多重新皮层区域搜索并巩固相关记忆,避免遗忘旧知识,同时学习新知识。核心思想:
提出 Elastic Semantic Network (Else-Net),通过动态搜索最相关的学习块,并使用新块存储新知识,有效避免灾难性遗忘。
2. 相关工作
2.1 持续学习
- 持续学习旨在模拟人类智能,持续学习新任务而不遗忘旧知识。
- 现有方法多集中在图像分类领域:
- GEM (Gradient Episodic Memory): 使用梯度记忆缓解遗忘。
- ReMind: 通过压缩表示回放以减少输入样本需求。
2.2 骨架动作识别
- 主流方法:基于 CNN、图卷积网络 (GCN)、时空图卷积网络 (ST-GCN)。
- 挑战:需设计能处理新任务且避免遗忘的网络。
2.3 动态网络架构
- SkipNet 和 MutualNet 等动态网络可根据输入数据调整架构。
- Else-Net 的动态学习块搜索功能受此启发,结合动作语义进行动态路径选择。
3. 弹性语义网络 (Else-Net)
3.1 模块架构
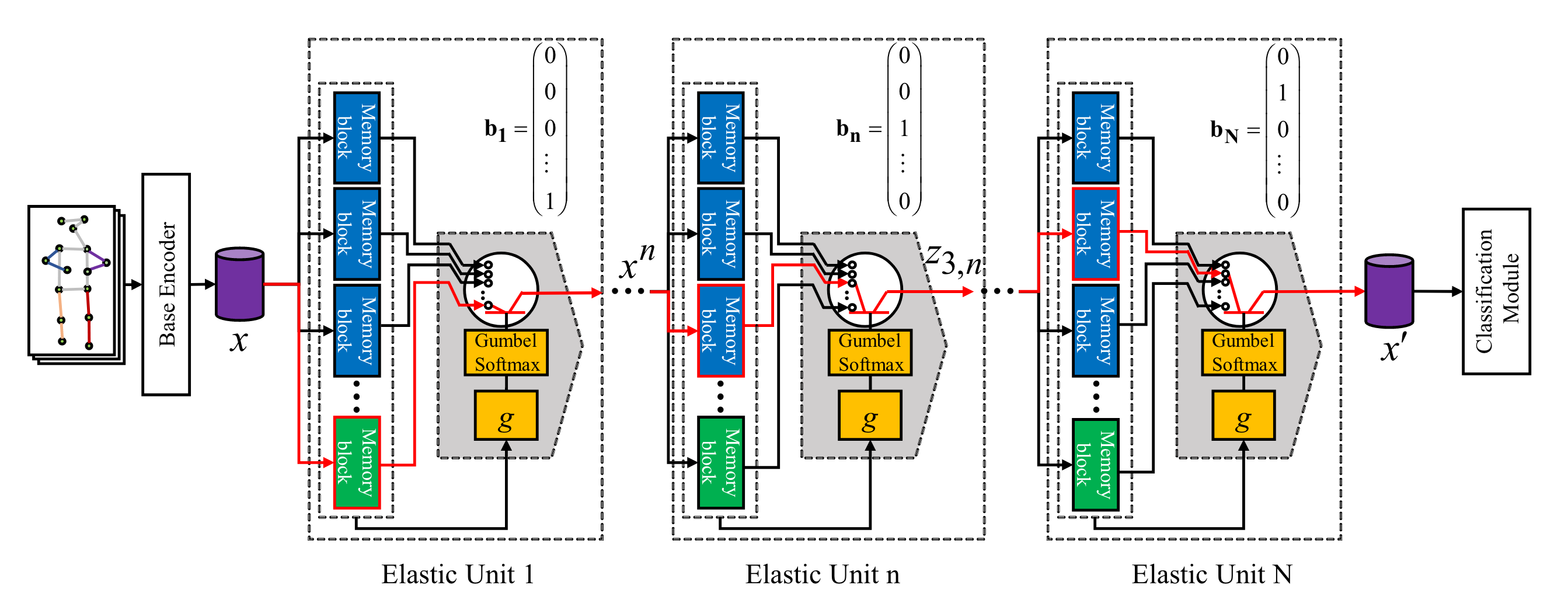
假设 Else-Net 包含 $N$ 个弹性单元(Elastic Units),每个弹性单元 $n$($n \in \{1, 2, \dots, N\}$)由若干学习块(Learning Blocks)和一个切换块(Switch Block)组成。学习块表示为:
其中,$\theta_{i,n}$ 是第 $i$ 个学习块的参数,$B_n$ 是第 $n$ 个弹性单元中的学习块数量。为了捕获新知识,第 $n$ 个弹性单元临时添加一个新学习块 $f_{\theta_{B_n+1,n}}(\cdot)$,以便存储新知识。
输入特征 $x_n$ 被传递给第 $n$ 个弹性单元中的所有学习块,生成对应的潜在特征:
这些特征通过切换块的门控模块 $g$ 和 Gumbel Softmax,生成一个 one-hot 匹配向量 $b_n$:
如果输入特征 $x_n$ 与第 $i$ 个学习块最匹配,则 $g(z_{i,n})$ 的输出值会高于其他块,并通过 Gumbel Softmax 将该块激活。
Gumbel Softmax:
假设给定概率分布 $ p = (p_1, p_2, \dots, p_n) $,Gumbel Softmax 通过以下步骤生成一个平滑的离散随机变量:
生成 Gumbel 噪声:
对于每个类别 $ i $,从 Gumbel 分布中采样 $ g_i \sim \text{Gumbel}(0, 1) $。计算加噪声的 logits:
其中,$ p_i $ 是类别 $ i $ 的概率,$ g_i $ 是对应的 Gumbel 噪声,$ \tau $ 是温度参数。
使用 Softmax 函数进行归一化:
这是一个平滑的概率分布,经过温度调节,可以用来近似离散采样。
采样:
通过这个平滑的概率分布,我们可以进行采样,得到一个类别的近似选择。
- 可微性: Gumbel Softmax 使得离散变量的选择过程可导,可以通过反向传播进行梯度优化。
- 平滑近似: 温度参数 $ \tau $ 控制了采样过程的离散度,当 $ \tau \to 0 $ 时,结果趋近于 one-hot 向量;而当 $ \tau \to \infty $ 时,结果变得平滑。
Gumbel Softmax 广泛应用于以下领域:
- 生成模型: 如生成对抗网络(GANs)和变分自编码器(VAEs)中,生成离散数据时,使用 Gumbel Softmax 来近似离散采样。
- 强化学习: 在强化学习中,使用 Gumbel Softmax 来处理离散动作空间,使得离散动作的选择可导。
- 自然语言处理: 在文本生成等任务中,使用 Gumbel Softmax 来平滑采样。
假设有三个类别的概率分布 $ p = [0.7, 0.2, 0.1] $,我们可以用 Gumbel Softmax 来选择一个类别:
- 为每个类别生成 Gumbel 噪声 $ g_1, g_2, g_3 $。
- 计算加噪声的 logits $ y_1, y_2, y_3 $。
- 用 Softmax 函数归一化并生成平滑的概率分布。
在给定温度 $ \tau = 0.5 $ 时,得到的 $ y_i $ 值接近于一个 one-hot 向量,表示选择某个类别。
Gumbel-Softmax 和 硬选择(Hardmax) 的区别
Gumbel-Softmax($\tau \to 0$):
- 概率分布:平滑的概率分布,温度趋近于 0 时,逐渐接近 one-hot 向量。
- 随机性:具有随机性,即使在温度较低时,输出仍然是基于概率的。
- 平滑性:随着温度的降低,逐渐过渡到硬选择,避免突然的离散化。
- 训练过程:避免了梯度问题,支持平滑的梯度传递,适合连续的训练过程。
- 适用场景:适合需要探索不同选择、避免过拟合的训练过程。
硬选择(Hardmax):
- 概率分布:直接选择最大概率类别,输出一个离散的 one-hot 向量。
- 随机性:没有随机性,始终选择最大概率的类别。
- 平滑性:没有平滑,直接进行硬选择,不能避免离散化过渡。
- 训练过程:由于没有梯度,可能导致训练不稳定。
- 适用场景:适用于需要明确选择类别且不需要平滑过渡的情况。
关键区别
| 特点 | Gumbel-Softmax($\tau \to 0$) | 硬选择(Hardmax) |
|---|---|---|
| 概率分布 | 平滑的概率分布 | 直接产生一个 one-hot 向量 |
| 是否具有随机性 | 具有一定的随机性 | 没有随机性,固定选择 |
| 平滑性 | 在 $\tau$ 很低时趋近于 one-hot | 没有平滑,直接选择最大值 |
| 训练过程 | 能够避免梯度问题 | 由于没有梯度,可能会导致训练不稳定 |
| 实现复杂性 | 需要计算 Gumbel 噪声并进行 softmax | 直接取最大值 |
总结
- Gumbel-Softmax 提供了平滑的过渡,避免梯度问题,适合需要探索的训练过程。
- 硬选择 是完全离散的,没有随机性和渐进的平滑过渡,适合需要明确类别选择的情况。
对于参数更新,仅更新与当前输入最相关的学习块参数,其余块的参数保持冻结。更新规则如下:
其中,$y_k$ 和 $\hat{y}_k$ 分别是当前输入的真实标签和预测标签,$b_{i,n}$ 是匹配分数($1$ 表示最佳匹配块,$0$ 表示其他块),$\alpha$ 是学习率。
交叉熵解释
该公式是交叉熵损失函数的一部分。在交叉熵损失函数中,每个类别的损失被计算为:
$\sum_{k} y_k \log \hat{y}_k$
这里,$(y_k)$是真实标签(one-hot 编码),而 $( \hat{y}_k )$ 是模型的预测值。
如果 ( k ) 是真实类别,则 ( y_k = 1 ),此时损失函数成为:
$\log \hat{y}_k$
这意味着,如果模型对正确类别的预测概率较高,损失较小;如果模型对正确类别的预测概率较低,损失会变大。
通过 $N$ 个弹性单元的最相关学习块连接起来,Else-Net 构建了一个最优的语义路径,利用已有知识高效地学习新动作。
3.2 Pathway Construction for Body Part Branches
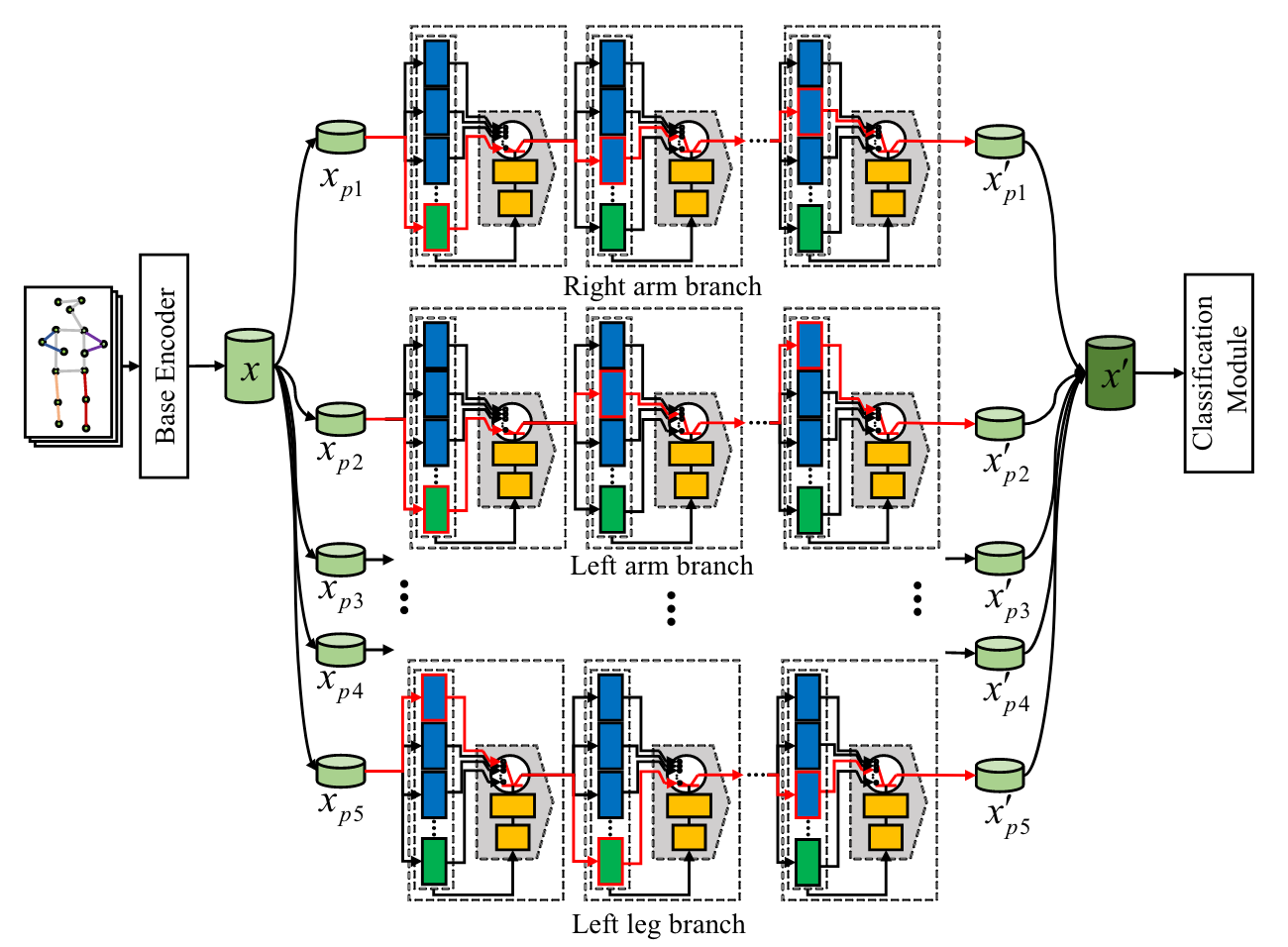
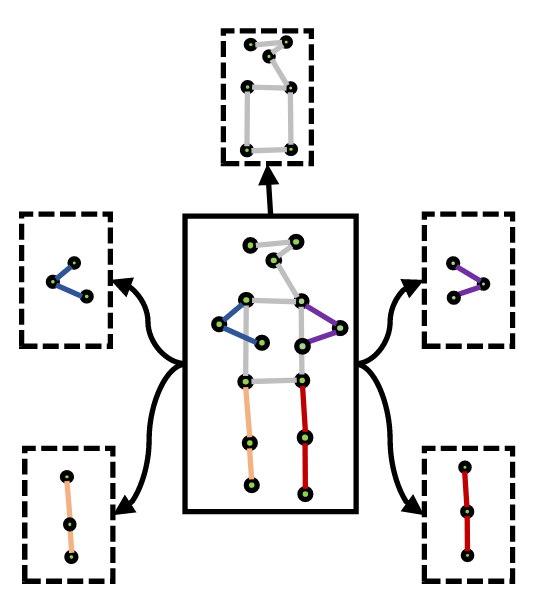
考虑到全身动作可能与先前动作差异显著,而局部身体部分可能存在共享的特征,Else-Net 将输入特征分解为五个身体部位特征:
对应左臂、右臂、躯干、左腿和右腿。每个身体部位分支的架构与全身分支相同,每个分支包含 $N$ 个弹性单元。
每个分支独立搜索和构建与当前输入特征最匹配的语义路径,分别生成每个部位的潜在特征:
最终,通过将这些部位特征拼接,得到完整的全身特征:
这种结构设计能够有效利用局部共享特征,提升对新动作的学习能力,同时缓解遗忘问题。
如何分解特征。
3.3 Training and Testing
训练阶段包括两个优化步骤:外部优化和内部优化。
外部优化
冻结所有学习块的参数,仅更新切换块的参数:
内部优化
冻结切换块的参数,仅更新选中学习块的参数:
其中,$\theta_g$ 和 $\theta_m$ 分别是切换块和学习块的参数,$b$ 是学习块的匹配分数。
测试阶段,输入动作通过语义路径搜索最相关的学习块,并生成全局特征,用于动作分类。
4. 实验
4.1 数据集
- NTU RGB+D: 60 类动作,56,880 视频,分为交叉视角和交叉主体两种评估协议。
- PKU-MMD: 51 类动作,1,076 视频,类似评估协议。
4.2 评估指标
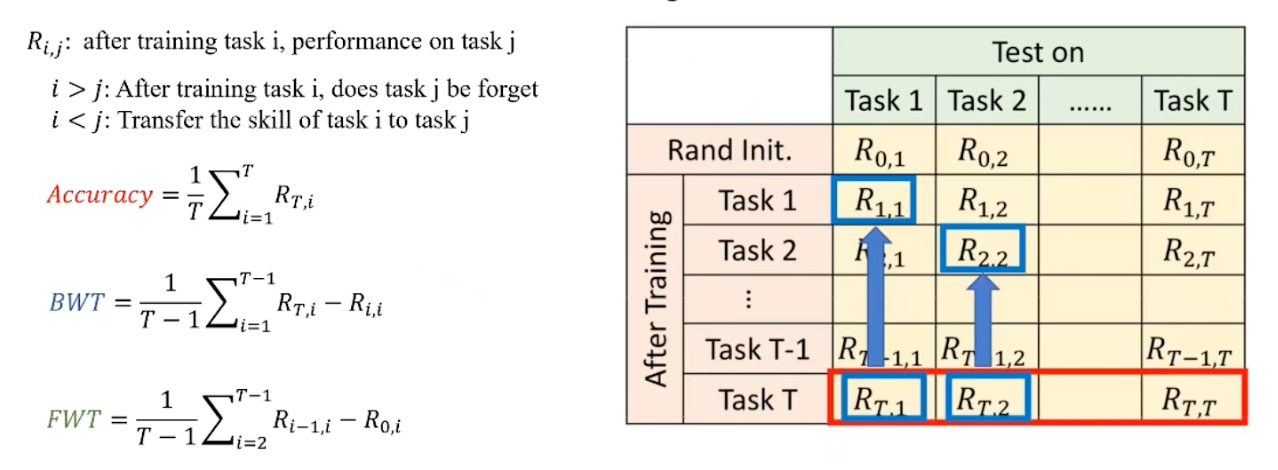
- 平均准确率 (ACC): 学完所有任务后,对所有任务的平均识别准确率。
$\begin{aligned}ACC=\frac1T\sum_{q=1}^Ta_{T,q}\end{aligned}$ - 遗忘度 (FM): 表征模型对旧任务的遗忘程度,越低越好。
$\begin{aligned}FM&=\frac{1}{T-1}\sum_{q=1}^{T-1}\max_{t\in\{1,2,…,T-1\}}\{a_{t,q}-a_{T,q}\}\end{aligned}$ - 学习准确率 (LA): 表征模型对当前任务的学习能力。
$\begin{aligned}LA=\frac1T\sum_{q=1}^Ta_{q,q}\end{aligned}$
4.3 结果分析
- 持续学习:
Else-Net 在两个数据集上均显著优于现有方法(如 GEM 和 ReMind)。 - 离线学习:
Else-Net 在离线学习设置下也取得与最优方法相当的结果。
4.4 消融实验
- 弹性单元数量: 增加单元数量可提升性能,但超过 3 层时增益减少。
- 部件路径的作用: 使用语义分支显著降低遗忘度,提高学习性能。
- 块搜索的作用: 动态块搜索避免混合噪声,提高知识保留能力。
- 选择性更新: 仅更新最相关块有助于知识保留和有效学习。
5. 结论
- Else-Net 模拟人类大脑,动态选择最相关学习块学习新动作,同时保留旧知识。
- 通过分解语义路径的构建,能更有效地捕获人体局部同质特征,缓解灾难性遗忘问题。
- 实验结果验证了 Else-Net 在持续动作识别中的有效性。