MAGR-CAQA持续学习
论文:MAGR: Manifold-Aligned Graph Regularization for Continual Action Quality Assessment
code:github
论文
面向FineDiving和LOGO(26个游泳项目),每个样本8名运动员
区别:传统持续学习,分类任务,AQA是回归任务。
两种回放方式:
经验回放:储存数据或特征。特征重放:有隐私保护的重放特征
创新点:新的特征重放方法-MAGR
使用的还是旧特征,还是一种经验回放。
有点类似:墙面背景变化去识别螺帽。
C3D骨干网络更新,适应新特征,存在与旧特征不匹配风险。
动态AQA:运动员在康复过程中的AQA,随着恢复而变化。
传统CL:主要在解决公式1。
改进点:有序均匀采样OUS,选择存储特征。
模拟真实世界的技能变化,我们提出了一种新颖的CAQA成绩递增设置:
按照分数分布提出不同的task,把数据集划分为不同分数的task。把AQA-7数据集里6个类别,只用了跳水,每个类别划分不同的task。每次训练只训练一个类别。
是否可以交换顺序?,先学习高分,在学习低分。
不同任务如何设置task,所有类别一起训练
MTL-AQA:是一起划分task:全是跳水,3m,10m,单人双人。
为什么不分类别?
每个task,少量样本训练,剩下样本微调,测试时对task所有样本评估。
训练
指标:aft好像是自己新建的。
Memory-Free Methods利用模型结构、正则化和优化策略来减轻灾难性遗忘
Memory-Based Approaches(基于记忆的方法)是持续学习中应对灾难性遗忘的一类重要策略。这类方法通过显式存储旧任务的样本或特征,在学习新任务时定期回顾
table-1:整体训练,用来证明模型有对所有数据学习的能力,改变流行数据后,因为遗忘导致能力下降。
在和持续学习对比,不是AQA对比。
fig-7: 每个task重放10个特征。
最后:
MAGR只适用于AQA任务,不知道和其他CL方法的对比是什么样的。从分类进入回归任务。
应该是属于持续学习领域的连续任务,而不是AQA领域的持续学习。
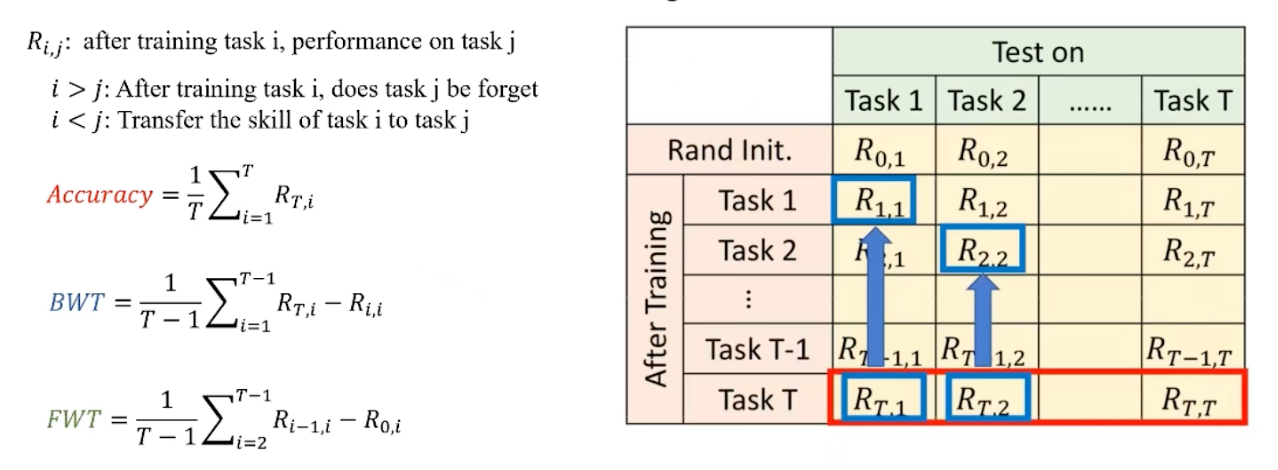
持续学习
主要方法:
正则化,元持续学习,记忆回放,在线和不平衡持续学习,方差减少技术。
图正则化:通过构建一个图,其中每个节点表示一个图像类别,边表示类别间的相似性(例如,猫和狗可能有相似的特征,可以有较强的边连接),模型在学习新类别(如马、鱼)时,通过图正则化避免过度更新与旧类别(如猫、狗)之间的边。
评价指标:
Mammoth库
代码结构
使用的mammoth库,github
代码结构:
mammoth/ |
getting started
fist steps
logs: under the data/results, change by base_path in CONF.
organized:
WandB:
use: --wandb_project, --wandb_entity
add in the observe, like:loss = loss1 + loss2
Training, Validation, and Testing
the validation set is disabled,only test and train.
Load and save checkpoints
training: --savecheckand --loadcheck arguments.python utils/main.py --savecheck=last:
last: save after last task
task: save after each taskpython utils/main.py –loadcheck=<path to checkpoint>.pt
Fast training & optimizations
use: –code_optimization 2 or -O 2
distrubuted training: use –distributed=dp
Scripts
scripts/prepare_grid.py: contains a grid_combinations dictionary
scripts/local_launcher.py: launch on local machine
scripts/slurm_sbatcher.py: launch on a SLURM cluster.
scripts/wandb_sync.py: syncing the logs produced by WandB
Registration of backbones and datasets
..
contents
Models
training and testing
named
implemented observe method
Evaluation
forward method in the base class ContinualModel by default
Attributes and utility methods
Automatic attributes: provides a few properties that are automatically set during the incremental training
Module attributes and functions
models.get_model(args, backbone, loss, transform,dataset):
PARAMETERS:
args (Namespace) – the arguments which contains the –model attribute
backbone (nn.Module) – the backbone of the model
loss – the loss function
transform – the transform function
dataset – the instance of the dataset
utils
models.utils.load_model_config(args, buffer_size=None):
Loads the configuration file for the model
datasets
backbones
Features and logits
returnt=’out’: the backbone returns the logits produced after the classification layer.
returnt=’features’: the backbone returns the features extracted immediately before the classification layer.
returnt=’both’: the backbone returns both the logits and the features (a tuple (logits, feature)).
代码复现
依赖
torch |
错误
OSError
OSError: image file is truncated
在class_seven.py中添加:
from PIL import ImageFile |
预训练模型一直在被改变?
命令
训练
python main.py \ |
损失函数
loss_d_score: 分数损失。mse_loss
loss_d_re: ListNetLoss排序损失。