GNN 图神经网络
博客链接:GNN博客
图是什么?
实体(顶点 node)之间的关系(边 edge)。A graph represents the relations (edges) between a colelction of entities(nodes).

Q2: attributes in V E U 重要吗?
!关心图的整个架构
!更关心 每个顶点、每条边、和 整个图表示的信息
Q3: attribute 如何表示呢?
Q4:数据如何表示成图?
图片如何表示成图?
244 244 3通道,3维度的tensor
把图片看作一张图,一个像素是一个点;一个像素跟我是连接关系的话,像素之间连一条边。
把图片上的像素 映射到 图上的每一个点
0-0 2-2
蓝色点 表示 adjacent matrix,白色点表示无连接;通常是很大的sparse matrix
什么可以表示为图
文本的顺序:图的有向路
Q5:除了图片、文本,还有什么数据可以表示成图?
香料分子图、咖啡因的分子图、社交网络图、引用图(directed)
相关问题
图有几类信息需要表示?
nodes V, edges E, global-context U and connectivity
V E U 可以用 vector 表示,问题是 connectivity 如何表示?by adjacent matrix?
Q6:n * n 的 0-1 元素矩阵 表示 connectivity 可以吗?
矩阵很大,i.e., wikipedia数据集,12M nodes,矩阵会有12M行、12M列,无法存储。
边通常是稀疏的,存储 sparse matrix ✔;但稀疏矩阵在GPU上的高效运算,难❌
邻接矩阵的 行、列顺序交换,不会影响图
图神经网络
输入一个高效存储、顺序无关的 Nodes, Edges, Adjacency List, Global 信息,如何用 NN 处理呢?—— Graph Neural Networks
图神经网络的定义
A GNN is an optimizable transformation on all attributes of the graph (nodes, edges, global-contex ) that preserves graph symmetries (permuation invariance).
图上属性的 可以优化的变化,且保持图的对称信息。
对 attributes 进行变换时,图的结构不变化
Un 全局向量, Vn 顶点向量, En 边向量 分别构造一个MLP, MLP的输入输出的大小一致。
3个MLP f_Un, f_Vn, f_En 组成一个 GNN 的层。
graph-in, graph out
MLP f_Un, f_Vn, f_En 分别对输入的 Un 全局向量, Vn 顶点向量, En 边向量 计算,得到更新 Un+1 全局向量, Vn+1 顶点向量, En+1 边向量 。
GNN predictions by pooling information
最后一层的输出,怎么得到预测值?
simplest: nodes prediction 顶点预测
分类预测: i.e., 空手道俱乐部喜欢 A 老师还是 B 老师
和 NN 类似,node embeddings 向量 接入 输出维度为 2 or n 的全连接层 + 一个 softmax,得到分类结果;输出维度为 1,得到回归结果。
最后一层的顶点进入 图中的 C_V_{i,n} classification 全连接网络,得到顶点的分类。
Note: 所有顶点共享一个全连接层 C_V_{i,n} 的参数。
GNN 之前的层,不论图有多大,一层里面只有 3 个MLP
- 所有顶点共享一个 MLP
- 所有边共享一个 MLP
- 所有的全局 U(哈哈哈,全局只有一个)不用共享。
complex: node predictions without node embeddings
对某个顶点分类预测,但是没有这个顶点的向量。
pooling 汇聚 (似 CNN 的 pooling)
与缺失点连接的边的向量 4个 + 全局向量 1 个 == 代表这个缺失点的向量,再做一个全连接层的预测输出。
假设:所有顶点、边、全局向量的维度一致;不一致,需要做投影。
别的缺失点,连接关系不一样,最后的向量也不一样。
V_n 是只有边、没有顶点的向量
E_n 是边的向量
Rho_{E_n —> V_n} 通过 pooling 汇聚从 边 +全局 到 顶点的信息, 进入顶点共享的分类层 C_V_n 之前,每个顶点都有自己的向量 embedding
Q: 只有 node embeddings 没有 边的向量,怎么办?
Rho_{V_n —> E_n} 把 node embeddings 汇聚到 vertex 边上。
一条边,连接两个顶点,2个顶点向量相加 (+ 全局向量)== 得到 边的向量,然后进入边共享的一个 MLP 预测分类网络,得到边的预测输出。
Q: 没有全局向量 U, 有 node embeddings, 对整个图做预测?

把所有的 node embeddings 加起来,得到一个全局的向量,进入全局的MLP,得到一个全局的预测输出。
总结:不论缺少哪一类 V E U attributes,pooling 汇聚得到缺失值 embeddings,进入MLP,得到预测值。
最简单的 GNN 示意图
input graph 经过 GNN blocks (每一个 block 里面有 3个 MLP对 V顶点 E边 U全局 attributes 更新)得到 一个同结构的 transformed graph, 但 V E U 属性值已被更新。
(if 某类 embeddings 缺失,通过其它 embeddings pooling 汇聚而来)
最后根据 V E U 某类属性做预测,接一个 MLP classification layer 输出预测信息。
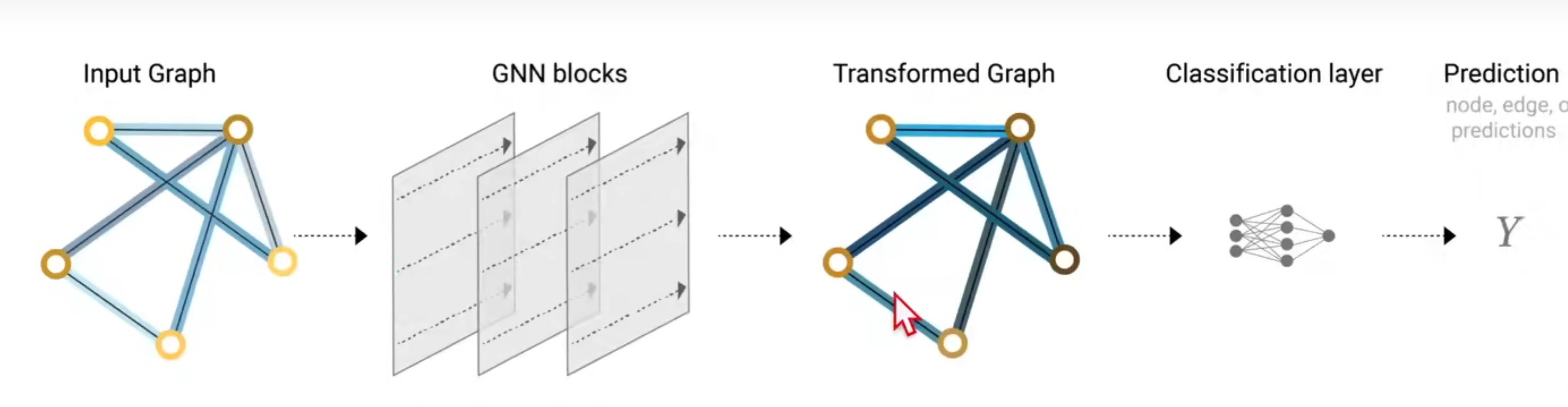
Q: simplest GNN 有什么问题?
GNN blocks 没有使用图结构信息:使用 MLP 更新属性值时,没有看到 V 顶点 E 边 的交互信息,只是 V 进 MLP_V, E 进 MLP_E, U 进 MLP_U,忽略了点边之间的连接信息。
overlook information: 一个顶点与哪些边相连,一个顶点与哪些顶点相连;一条边与哪些顶点相连,一条边与哪些边相连
GNN blocks 没有合理的将整个图的信息更新到属性值里,最后的结果不能 leverage 图的信息。
Q: 如何改进 GNN blocks 以考虑图的结构信息?
信息传递
Passing messages between parts of the graph
类似 pooling 汇聚
顶点的向量和邻居的向量相加,进行MLP变换。
对图中顶点进行更新,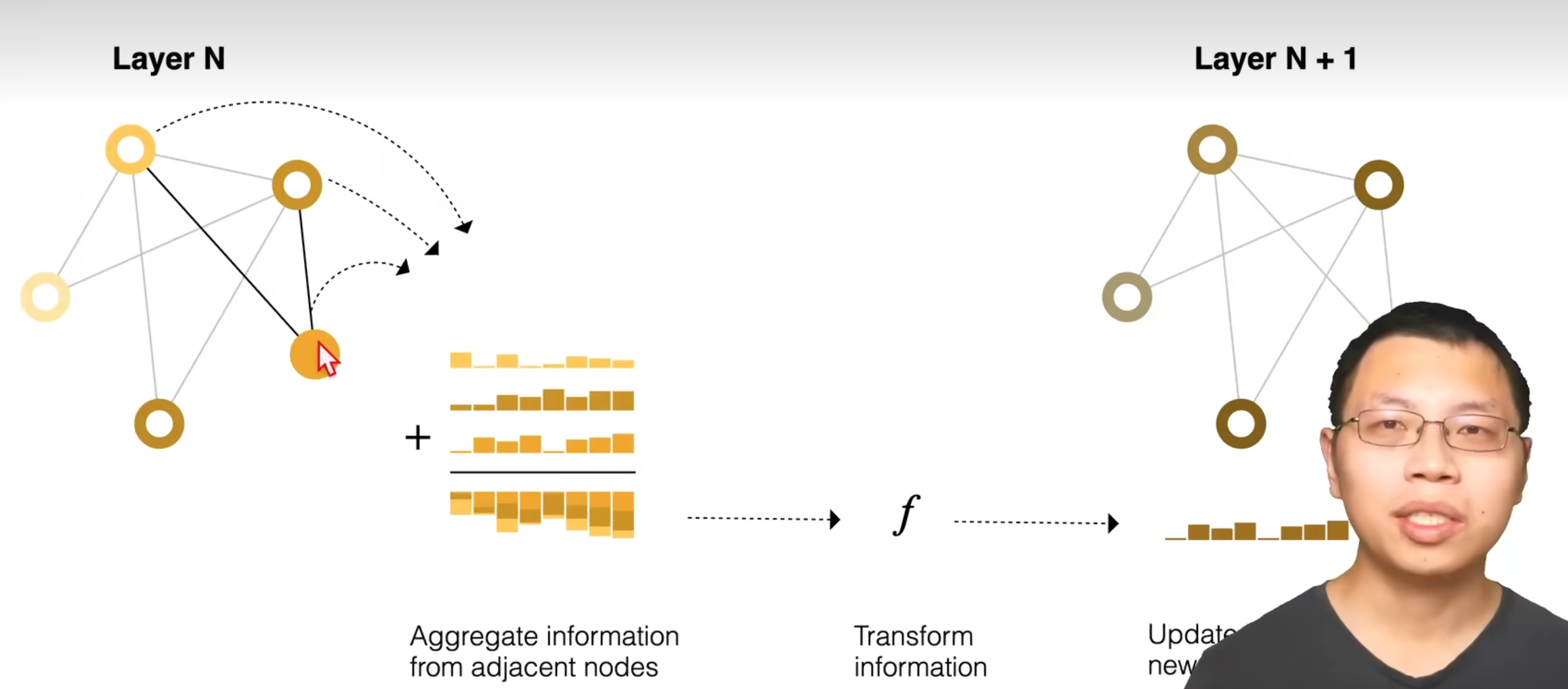
和卷积的不同,卷积的核权重每一个都不一样,GNN权重都是一样的,直接相加。
实验
GNN 对超参数比较敏感:
多少层、attribute的embedding的维度、汇聚使用什么操作max average、怎样传递消息
相关技术
除 GNN 外,还有别的图吗?
Multigraph
一张图中的多种边:有向边、无向边;分层图,一些顶点是子图的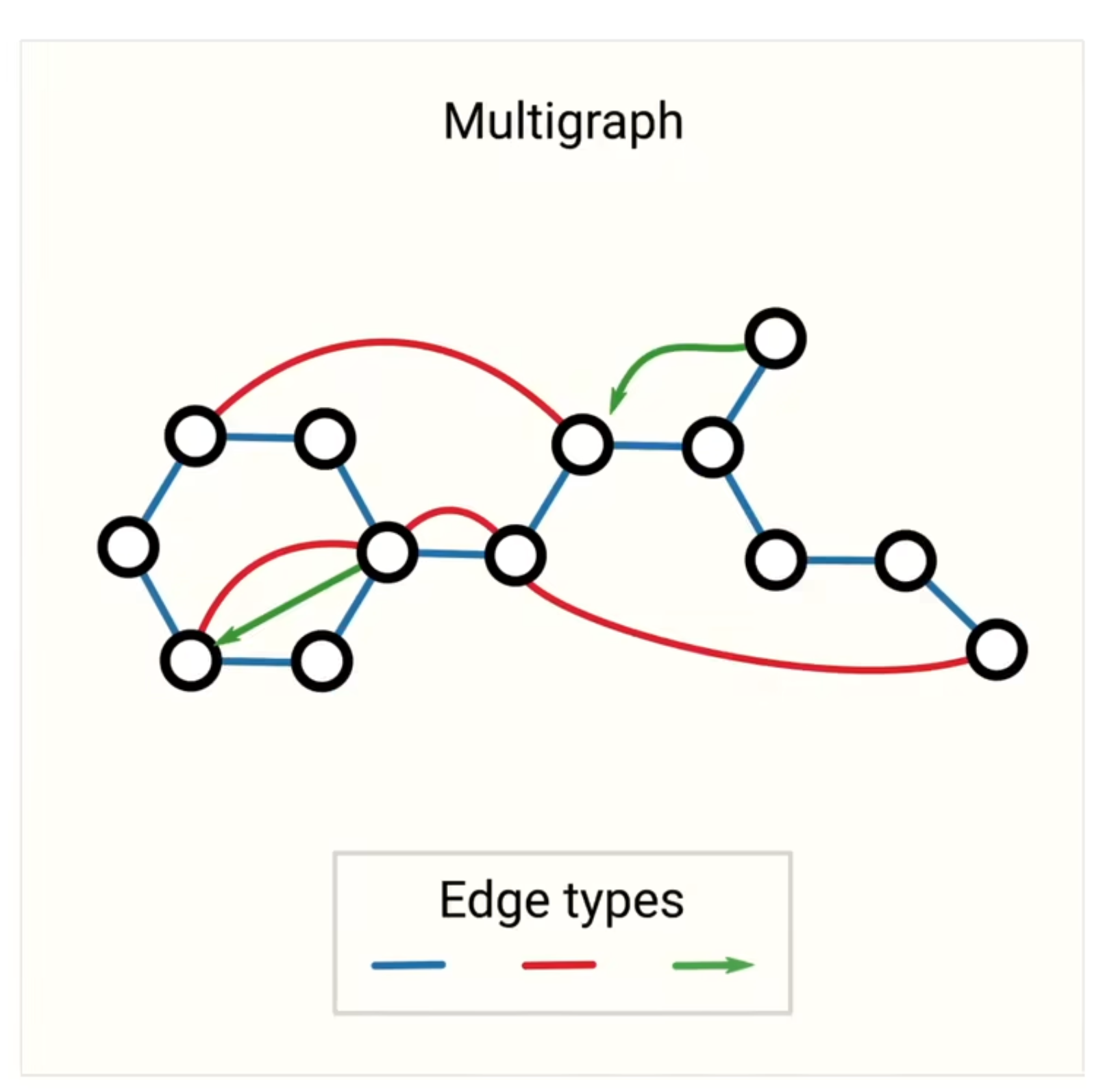
不同的图结构 影响 message passing 的操作
Sampling graphs and batching in GNNs
Why sample graphs?
i.e., 一个有很多层、很大的图
最后一层的顶点,即使只看每一层的一阶邻居,根据消息传递,最后一层的顶点能看到一个很大的图,甚至是全图的信息(如果图的connectivity可以的话)
计算梯度需要 forward 过程中全部的中间变量。因为最后一层的顶点要看整个图的话,对最后一层的顶点计算梯度,需要把整个图的计算中间结果都保存下来,—> 计算难 /(ㄒoㄒ)/~~
—> sample graph 采样
类似候选框
sample graph 的方法有哪些呢?
- random node sampling
采样 4 个黄色nodes,得到 1-degree neighbor 红色点
只在 sample 出来的子图上做计算,避免图特别大、内存存不了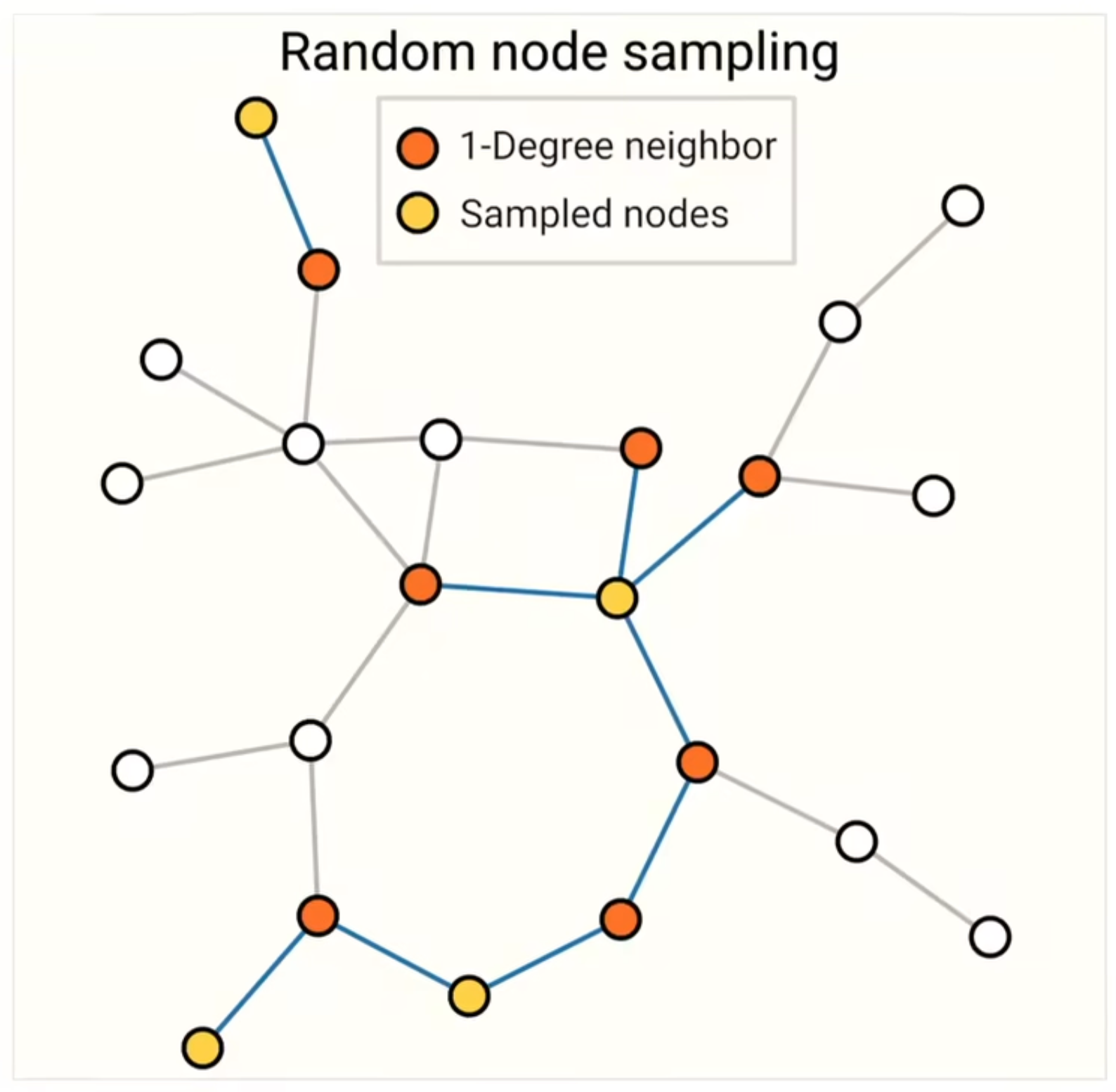
- random walk sampling
随机游走
从某一个顶点开始,随机找一条边,然后沿着这条边走到下一个节点
规定最多随机走多少步,得到一个sample子图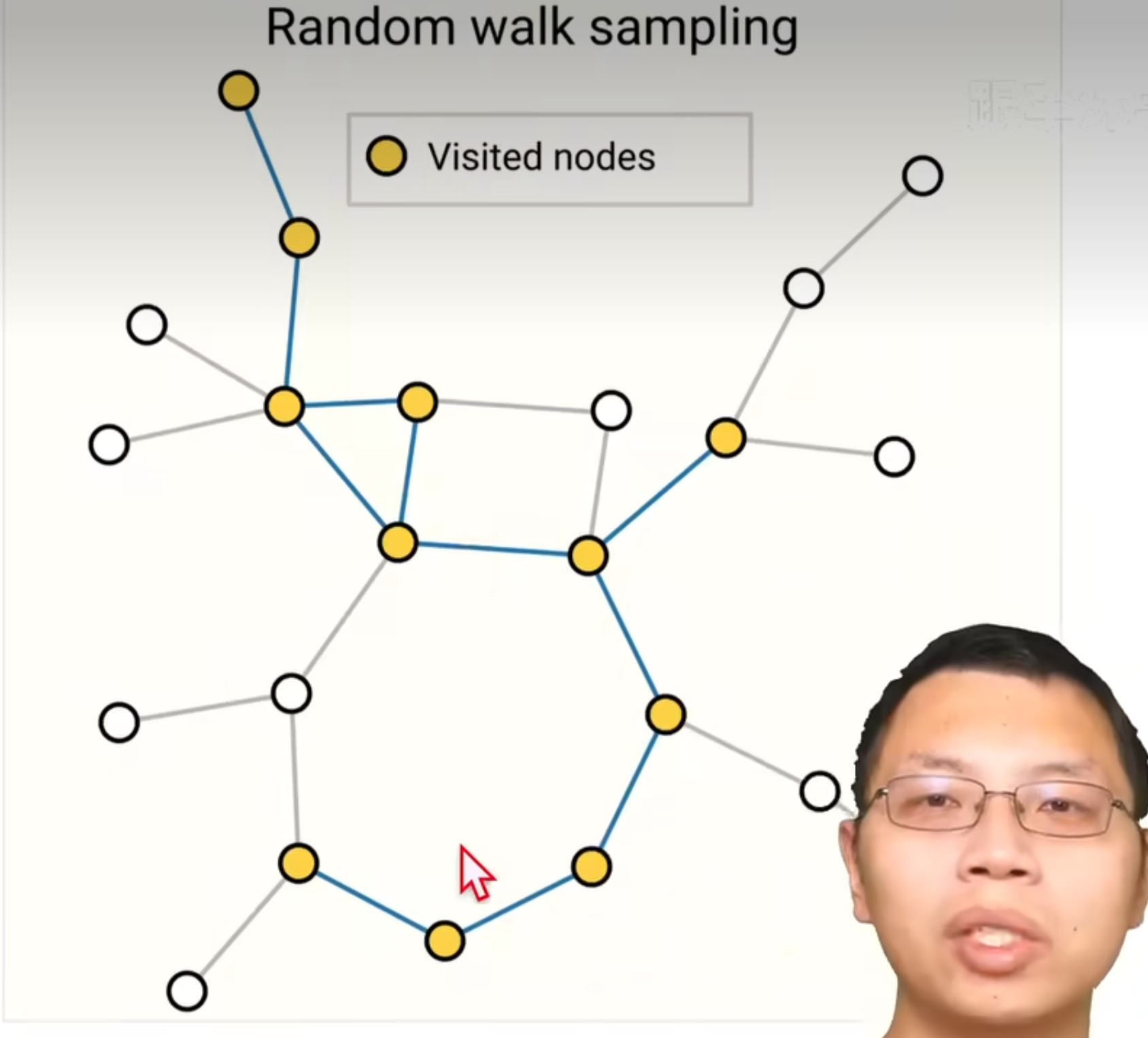
- 1 + 2
随机走三步,走到的节点的邻居也考虑进来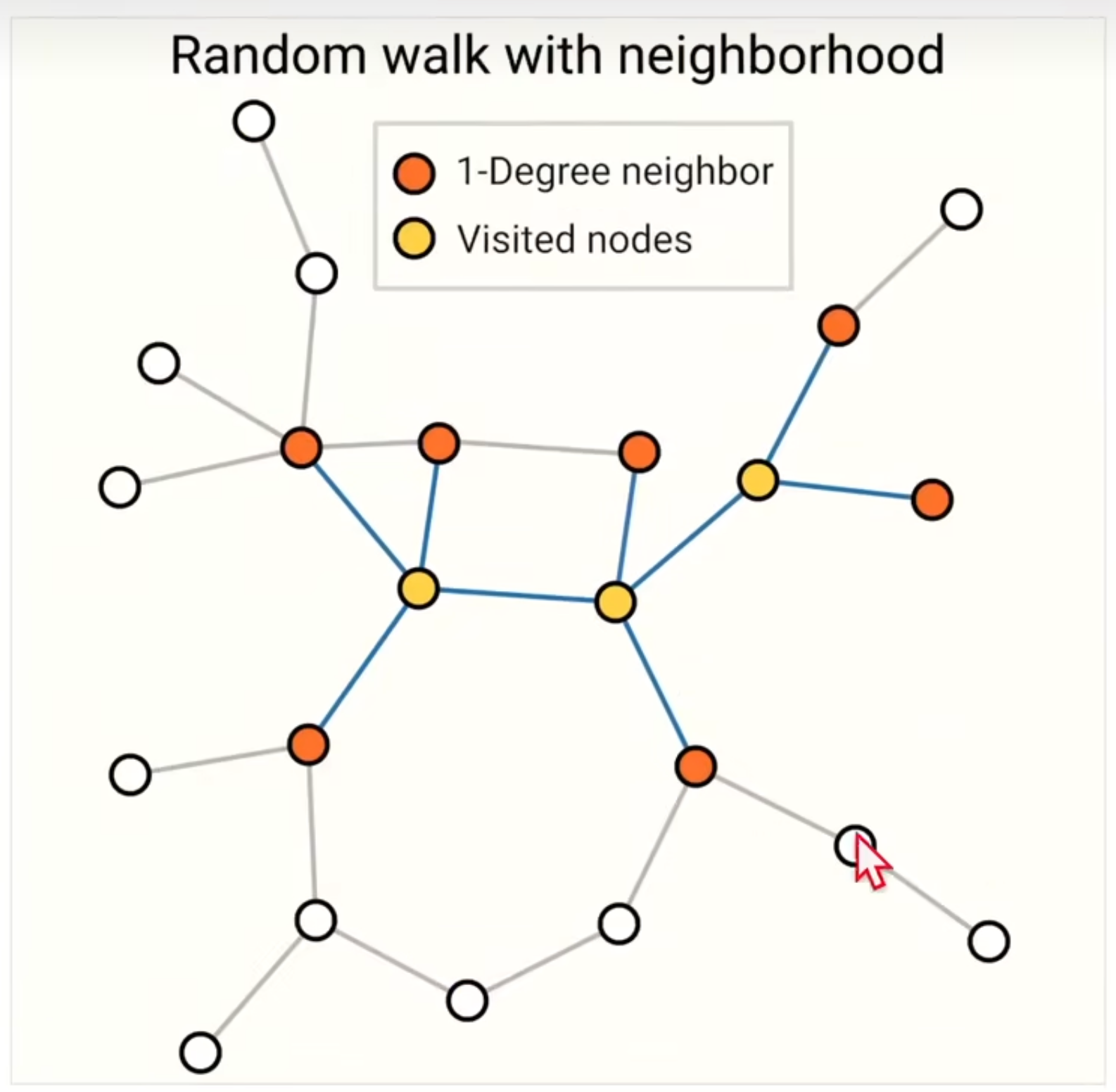
- BFS
取一个点及其一阶、二阶邻居,然后再往前走 k 步,得到子图
4 种 sample graphs 的方法取决于数据集的形式
讨论
卷积神经网络:假设空间变换不变性
循环神经网络:假设时序延续性
图神经网络:假设保持图的对称性:不管怎么交换顶点顺序,GNN的作用都不变。
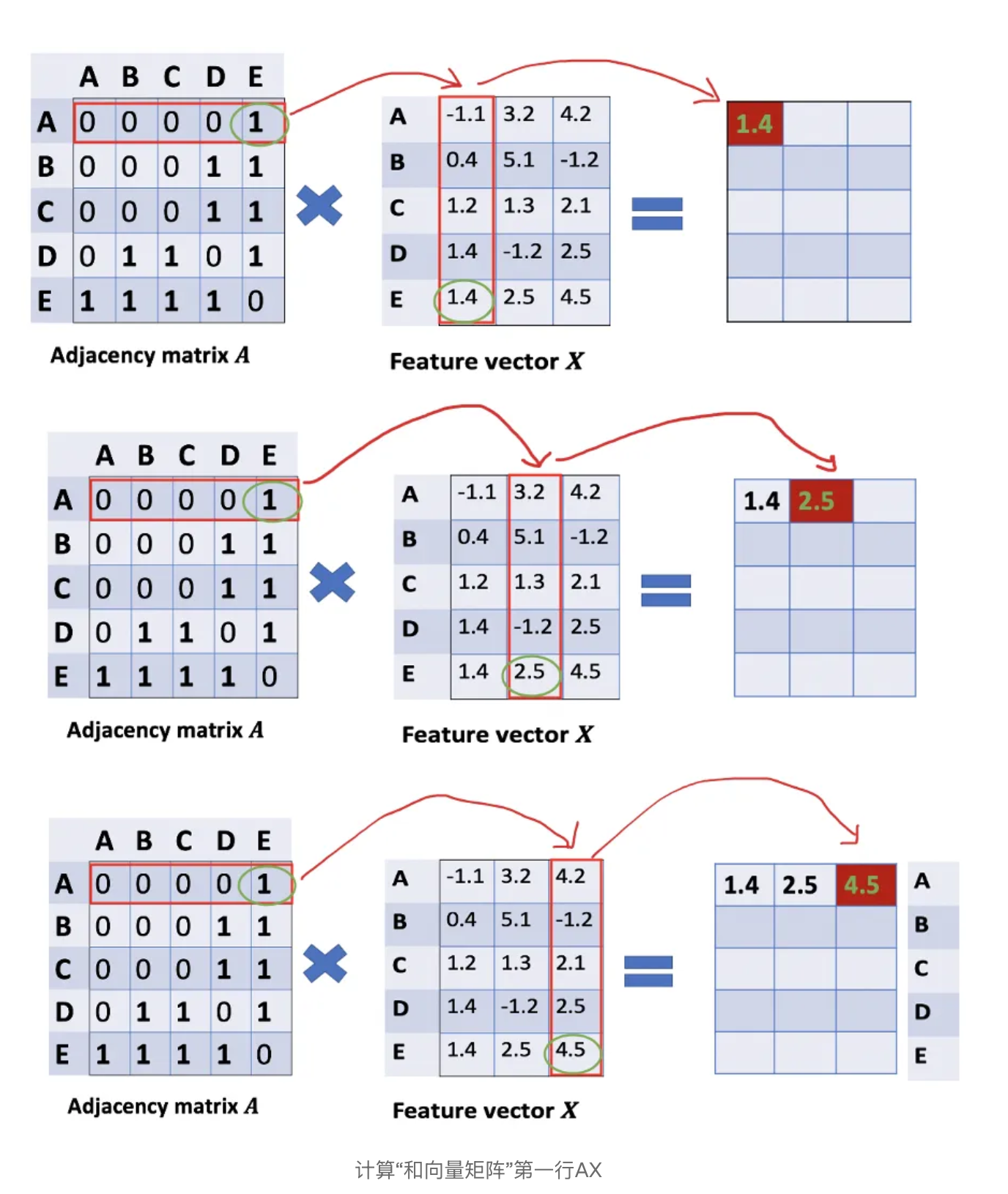
GCN:图卷积神经网络,图神经网络做了汇聚操作。
GCN的汇聚操作,是如何把相邻节点的特征权重$W$或者$X$,通过邻接矩阵汇聚更新到自己。