13-丢弃法
动手学深度学习李沐
更新历史
- 24.04.24:初稿
系列
13-丢弃法
1.丢弃法动机、实现及原则
1.1动机
- 一个好的模型需要对输入数据的扰动鲁棒(健壮性)


1.2如何实现模型的这一能力
- 使用有噪音的数据。
- 丢弃法:在层之间加入噪音。
1.3加入噪音的原则
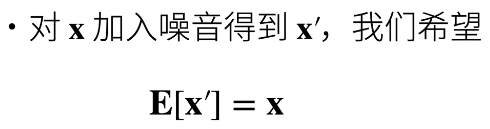
- 例如模型的功能是识别猫猫,加入噪音可以是输入模糊的猫猫图片,但尽量不要是狗狗的图片。
2.丢弃法内容
- 丢弃法对每个元素作如下扰动
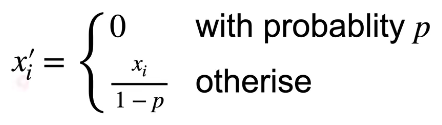
- 能够满足加入噪音的期望相同原则
- 一定概率变为0,一定概率变得很大
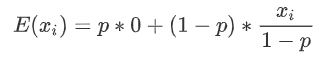
- 期望没有发生变化,分母的意义
3.丢弃法使用
3.1丢弃法的使用位置
- 通常将丢弃法作用在隐藏全连接层的输出上
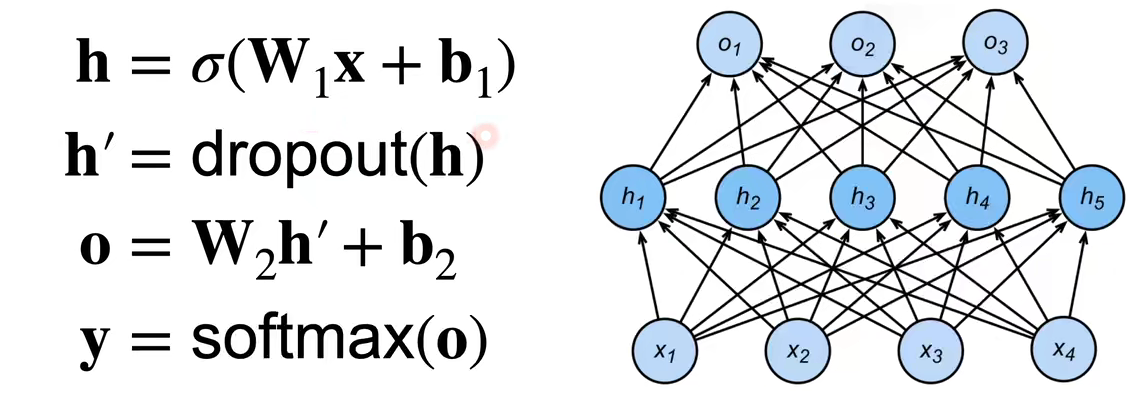
- 随机选中某些神经元将其输出置位0,因此模型不会过分依赖某些神经元
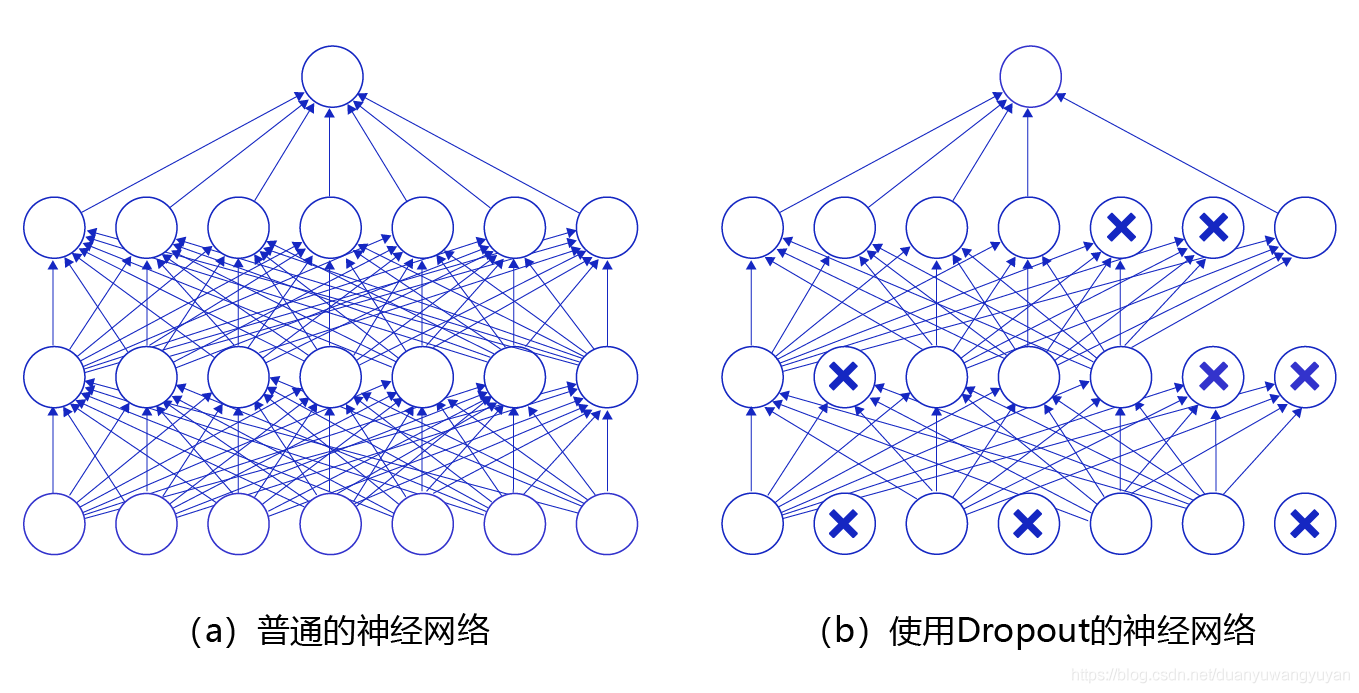
3.2训练中的丢弃法
- 正则项(丢弃法)仅在训练中使用:影响模型参数的更新,预测的时候便不再使用
4.总结
- 丢弃法将一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数(常取0.9,0.5,0.1)
5.代码部分
5.1Dropout部分
import torch |
5.2在神经网络中使用丢弃法
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256 |