CSAPP 笔记五 优化程序性能
更新历史
- 23.07.06:初稿
系列
Overview
通过查看汇编代码,对没有优化的代码进行调整。
Generally Useful Optimizations
Code Motion:代码移动,把常用的结果存到循环外。优化等级1以上,编译器会自动完成这个工作。
Reduction in Strength:减少计算量,乘法换左移或加法。
Share Common Subexpressions:寻找公共表达式,减少计算量。
Optimization Blockers
Procedure Calls:循环中进行相同结果的重复调用。
编译器无法优化的原因:
1.不知道是否在循环中修改了字符串;2. 文件单独编译,编译器不知道函数使用的是哪个文件中的函数,编译器事先假设函数是一个黑盒。
Memory Matters: 循环中重复读取内存。
无法优化的原因:
编译器不确定C语言是否存在内存别名,之前的结果会不会影响下一次读取的内存值。所以每次都进行读取写入操作。
Memory Aliasing:引入局部变量防止内存重叠。
Exploiting Instruction-Level Parallelism
采用指令级并行,适用于各种机器的通用优化方法
Benchmark Example
基准例子,使用一个抽象的数据结构。

Basic Optimizations
计算数组长度移出循环
移除边界检查,用新函数获取数组
引入局部变量

优化后性能:
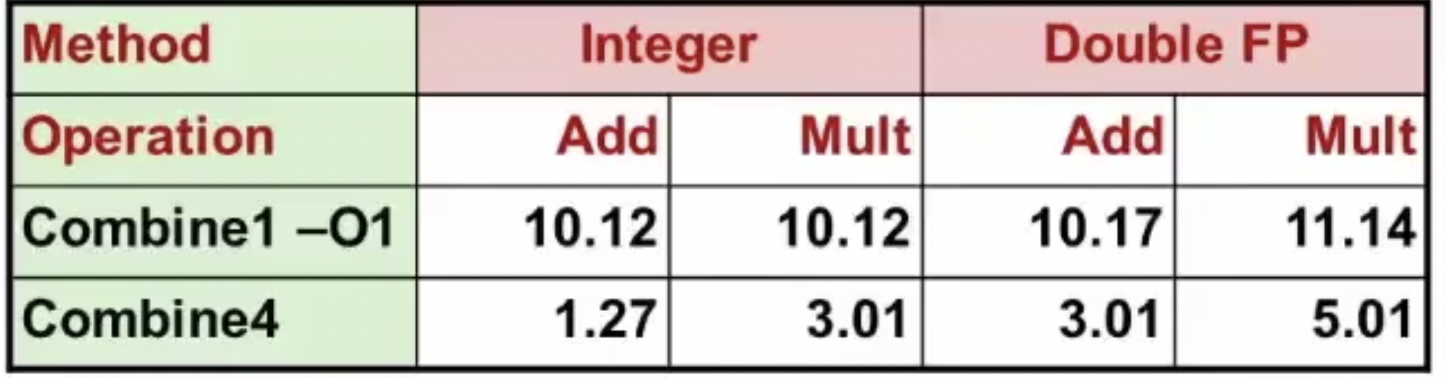
优化的基本限制: 程序限制了整数和浮点数的乘法必须顺序执行,所需要的周期为3和5。
Modern CPU Design
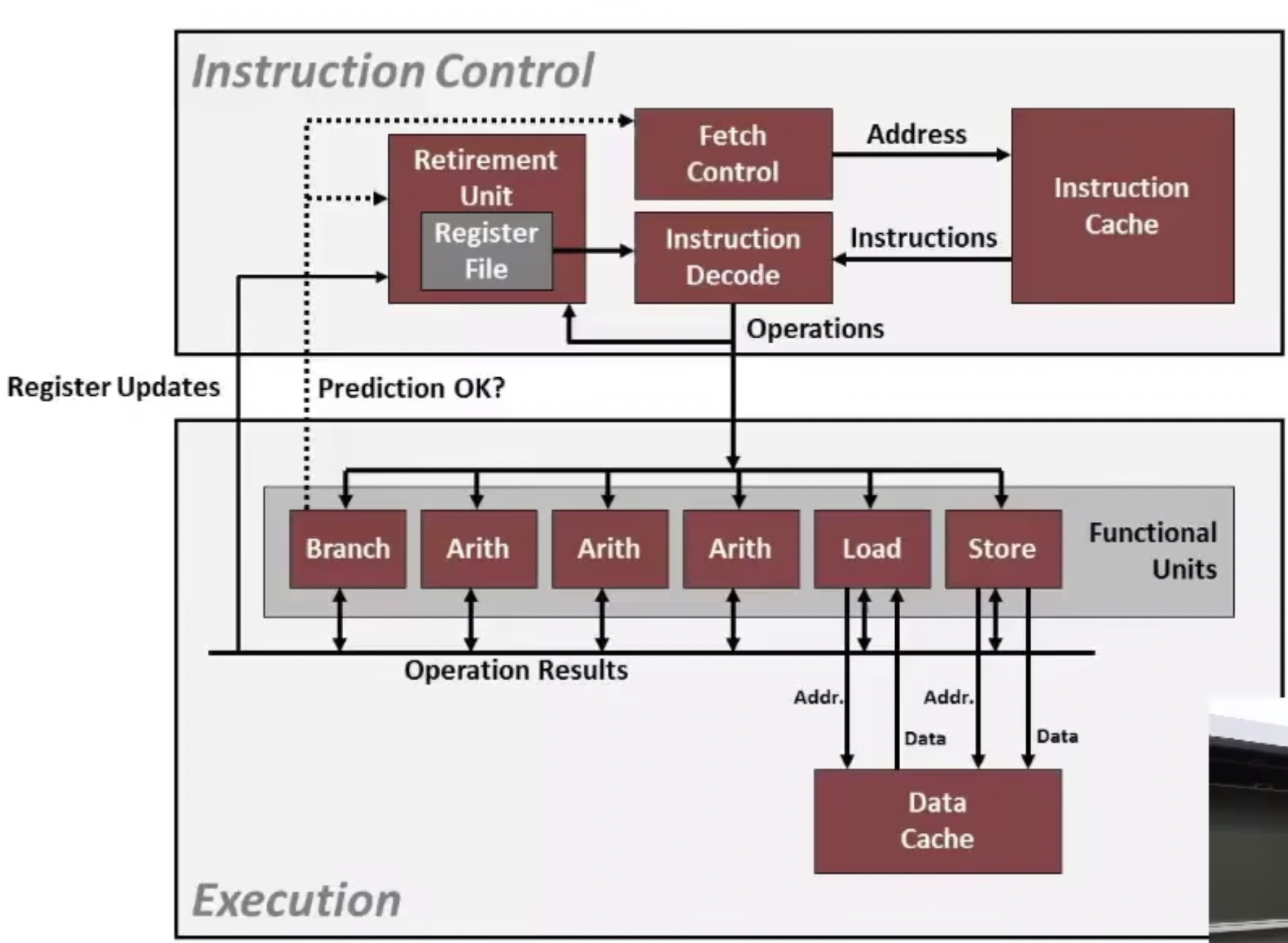
1995年的CPU,了解流程。
超标量乱序执行:顺序指令分解重组,实现指令级并行。
Superscalar Processor:超标量处理器
Pipelined Functional Units
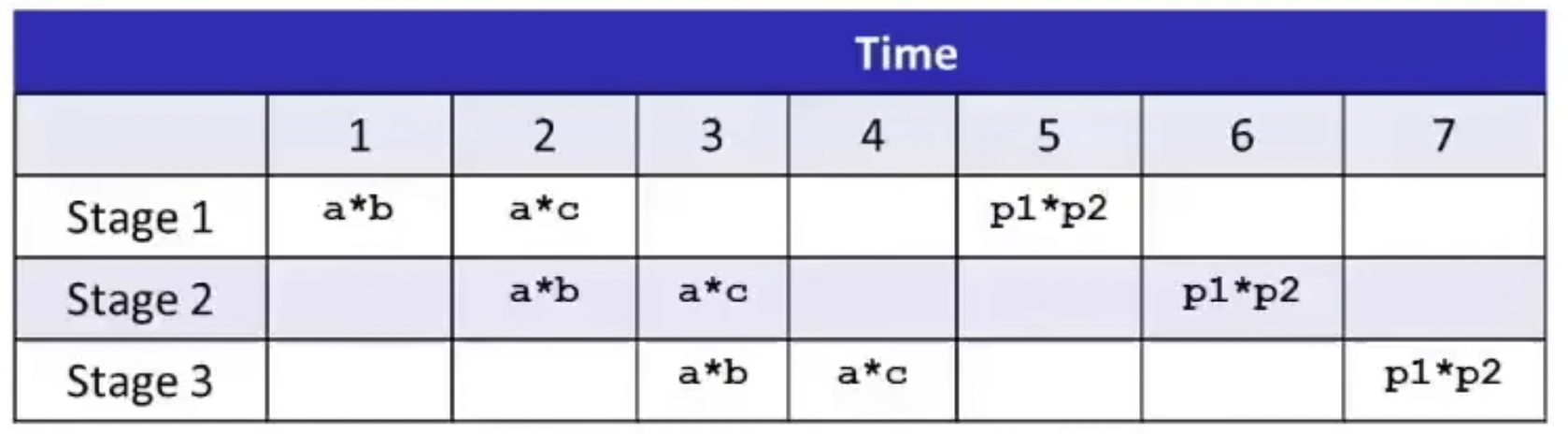
指令流水线:这里假设指令需要三个阶段完成
Loop Unrolling
循环展开: 循环中计算多个值,而不是计算一次。

每次循环计算两个操作数
limit: n-1, 循环i跳出时满足 i + 1 < (n - 1) + 1 = n;
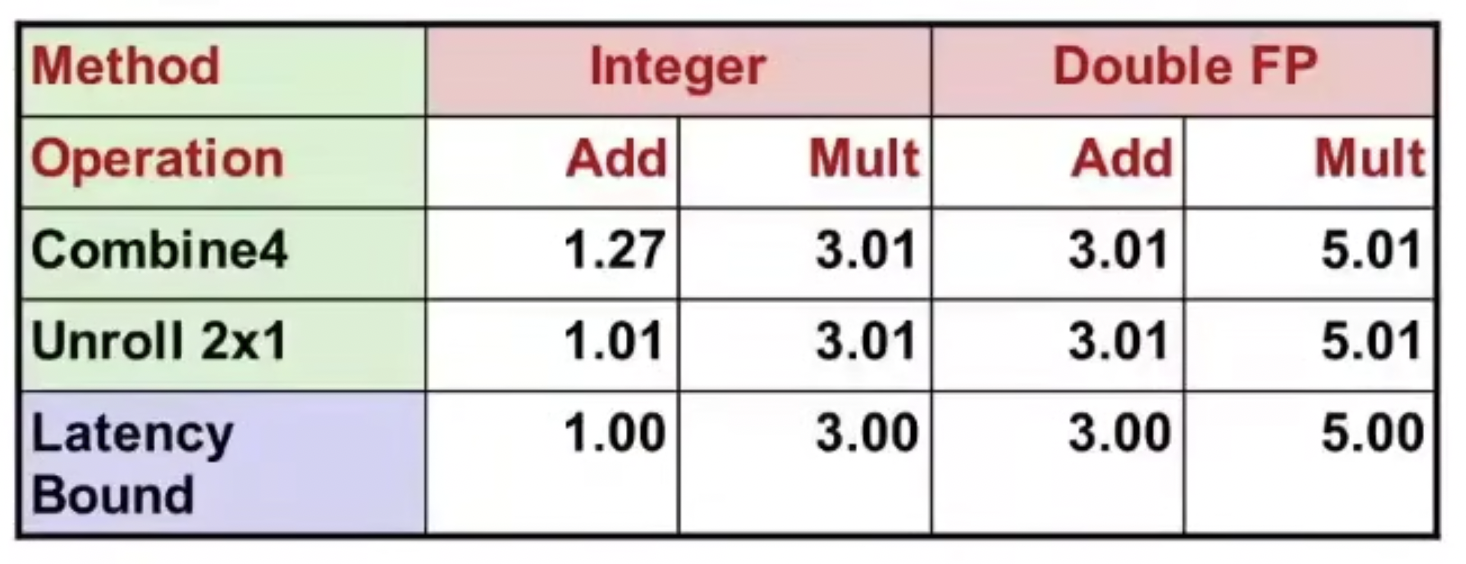
只有加法的CPE有了提升,降低了循环计数的消耗。其他没用提升是因为接近了延迟界限。
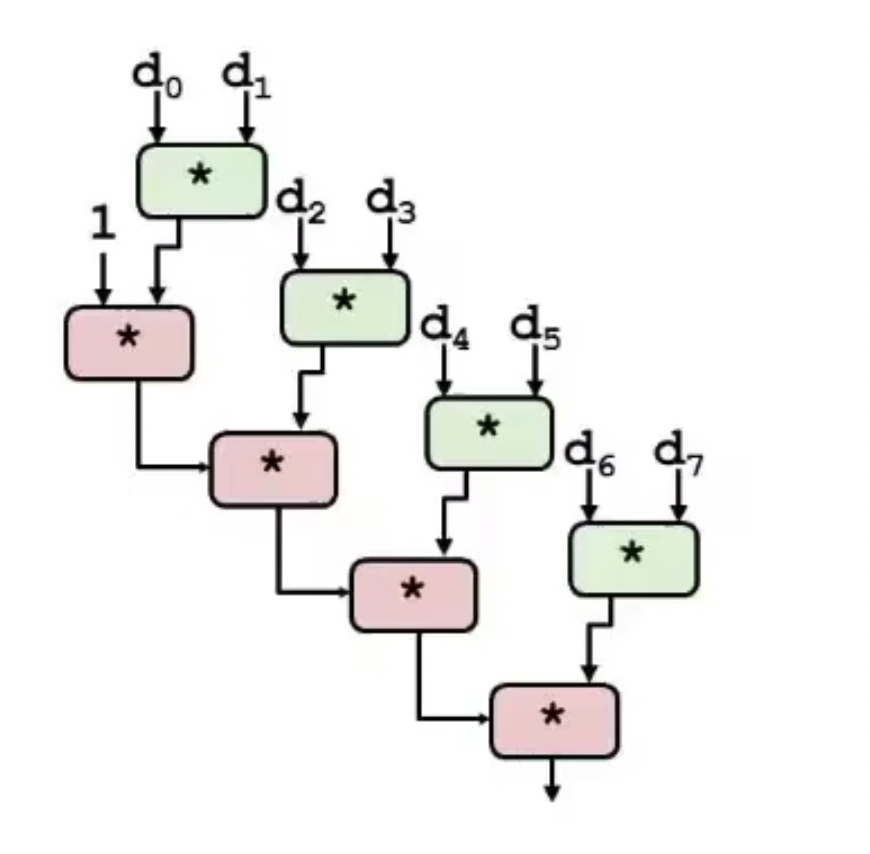
调整循环展开的计算顺序:
x = x OP (d[i] OP d[i+1])
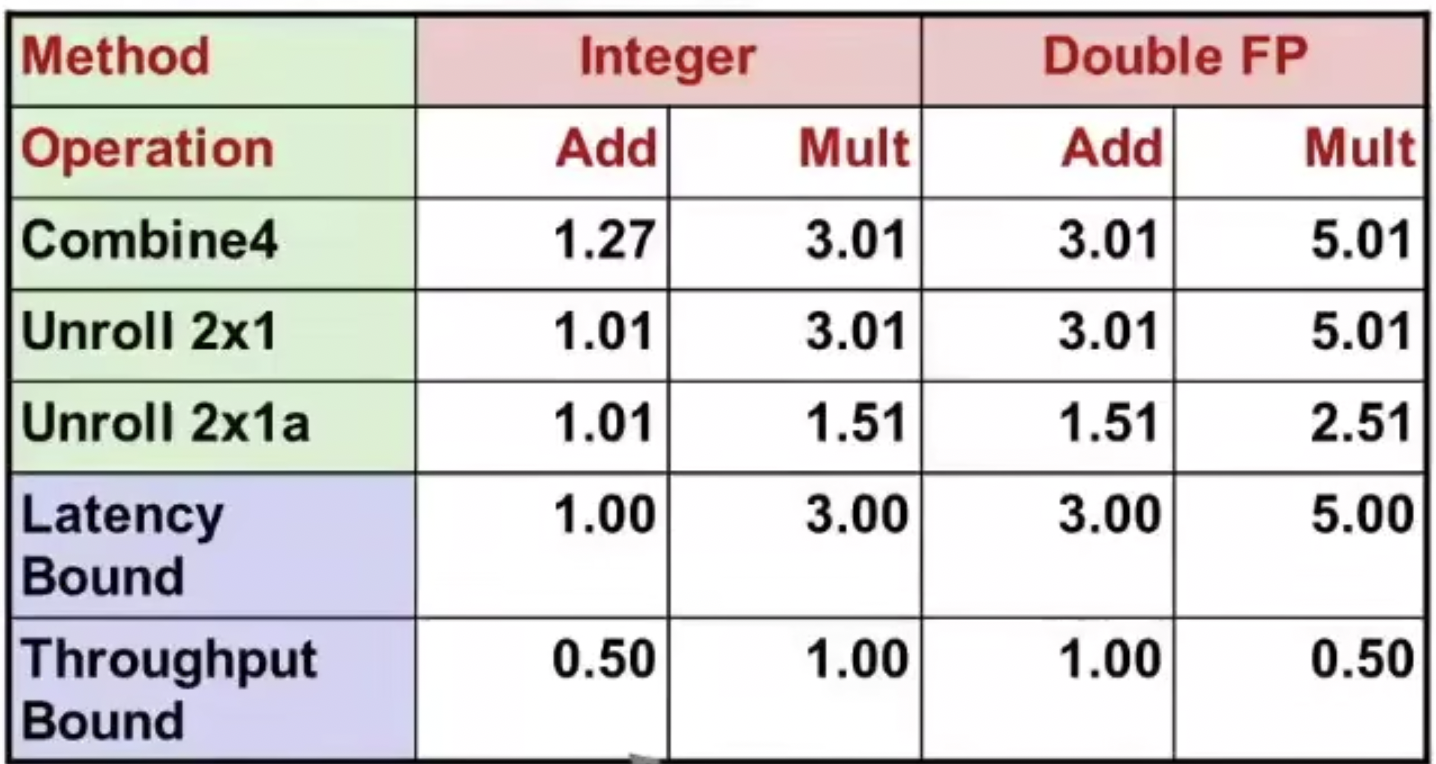
吞吐量突破了延迟界限,浮点数两个乘法器,一个加法器。
减少了计算的依赖,两个元素的计算不需要等上一个x的结果。浮点数不满足结合律,改变括号可能会发生舍入溢出,结果发生变化。
Latency Bound:严格顺序执行时,一条指令需要花费的全部时间。
Throughput Bound:基于硬件数量和性能限制,只有两个load单元,吞吐量为0.5
Separate Accumulators
多累加器,改变元素组合的顺序,如奇偶分开。
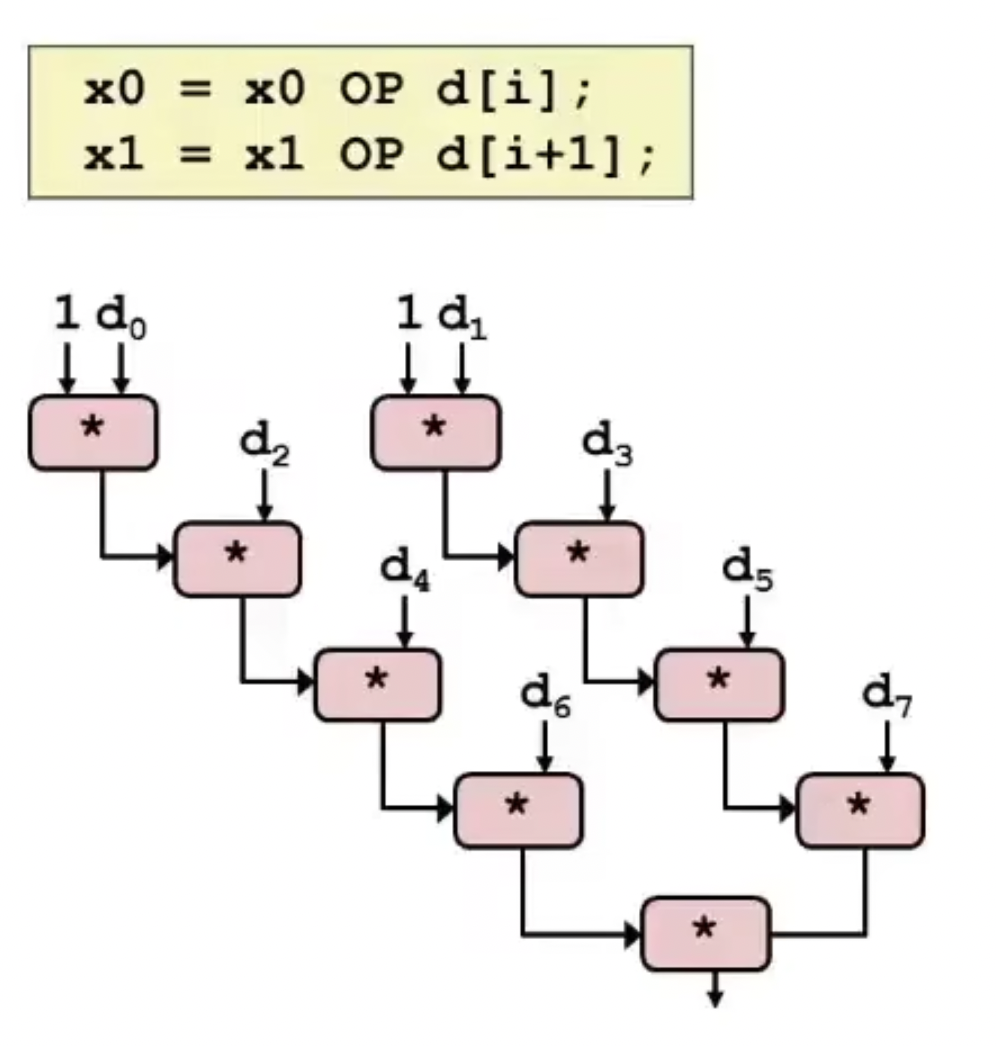
Unrolling & Accumulating
以K为因子展开一个L长度的数组,CPE可以接近吞吐界限
Programming with AVX2
YMM Registers
总共有16个32字节的寄存器 ,是%XMM的二倍。
SIMD Operations
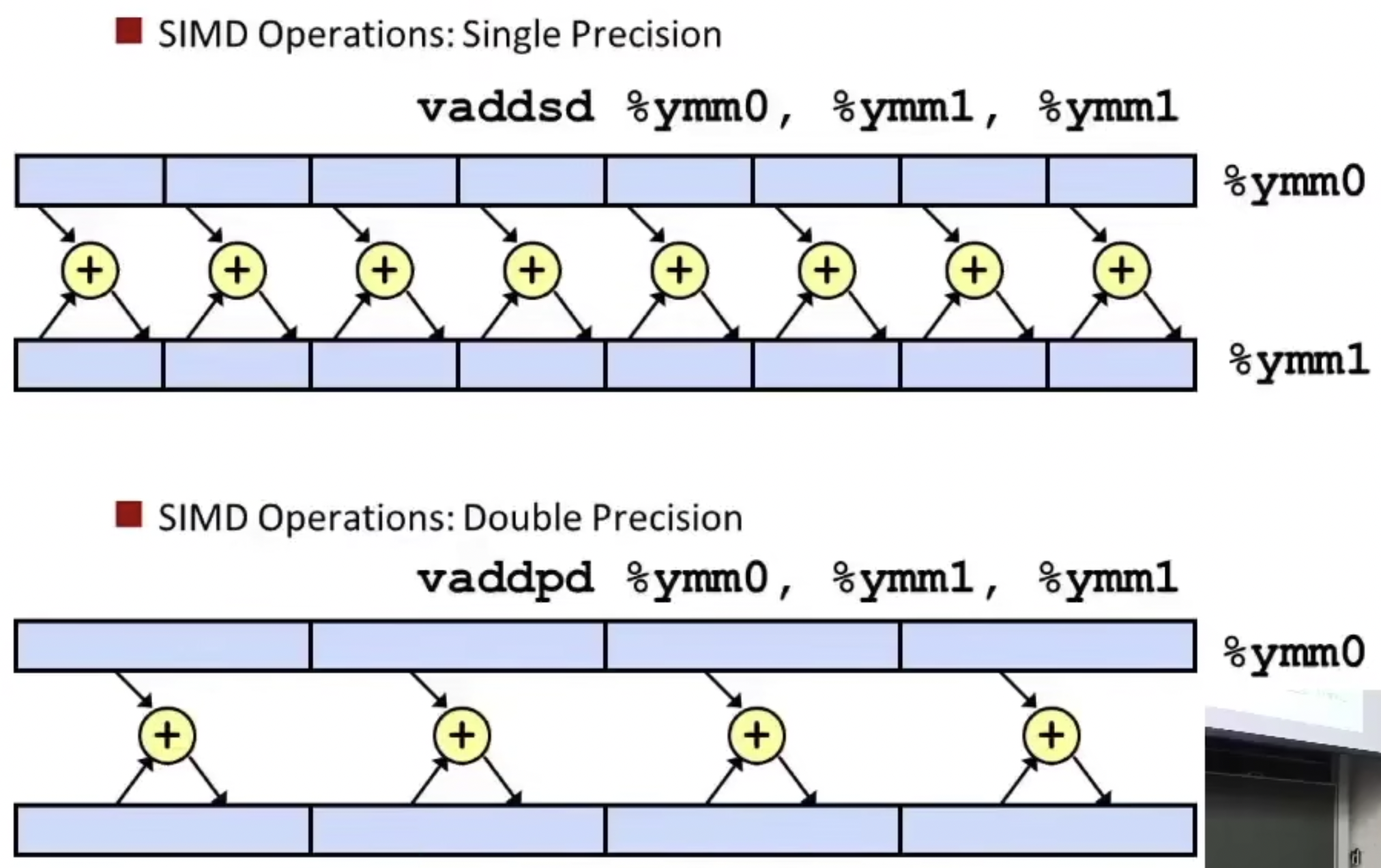
Vector Instructions矢量指令:并行执行八次单精度或四次双精度浮点操作
矢量指令是为处理视频,声音,图形引入的
gcc对矢量指令的优化是有限的
Dealing with Conditionals
What About Branches?
Branch Prediction
分支预测技术:先执行猜测的分支,然后再判断分支是否正确
所有的分支预测结果都写在寄存器副本中,错误时会回退正确的寄存器结果
Performance Cost
执行代价就是用了很多时钟周期处理所有的分支指令,可能会执行大量无效操作